zhuanlan.zhihu 高并发编程--多处理器编程中的一致性问题(上)
NOTE:
1、这篇文章写得非常好
"Multithreading is just one damn thing after, before, or simultaneous with another. "[2]
0 写在前面
在分布式存储系统中,为了提高**可靠性**,通常会引入多个副本,多个副本需要向用户表现出一致的内容。这很自然的让人想到如何确保多副本之间的一致性。为此也有了paxos和raft等保证多副本之间一致性的协议。当我们在一个多处理器机器上编程时我们通常会忽略在多处理器环境下的一致性问题,因为系统已经为我们做好了基本的**一致性**保证,当存在一致性问题的时候上层编程语言也提供了具备一致性语意的接口,只是我们在编程中并没有意识到这些**接口**与**一致性**的关系。无论是分布式存储还是多处理器编程都有一个共同点,就是会涉及共享对象的操作。
NOTE:
1、"可靠性",其实就是HA
"多个副本",其实就是master-slave
"一致的内容",其实就是consistency
"共享对象"其实就是multiple model中的shared data
2、上述其实可以使用multiple model-shared data来进行描述
一旦出现共享,就会出现正确性的问题,那么如何定义在并发中操作共享对象的正确性,这就是一致性协议的任务了。
本文主要针对多处理器系统中的一致性问题进行了一些总结,对于分布式中的一致性问题会在后面文章中总结。
多处理器中的一致性问题源于并发,源于共享。对于共享内存并发操作下的正确性保证是硬件设计者需要提供给上层开发人员最重要的保证。对于上层开发人员来说,系统内部的一致性是透明的,但是去了解系统内部一致性的设计及原理有利于我们更能够面向机器编程,写出正确的代码。
由于水平有限,文中如存在问题,请帮忙提出。
1 本文主要内容
本文主要包括以下内容:
1、cache coherence
- cache design
- cache coherence protocol
- store buffer & invalidate message queue
- memory barrier/ fence
2、memory consistency
- consistency 分类定义
- SC
- x86 TSO
- relaxed memory model
3、C++ memory order
- memory model and memory order
- memory order release/acquire
- memory order sequence
- memory order relaxed
4、Synchronize
- insight lock
2 cache coherence[4]
一致性的任务就是保证并发操作共享内存的正确性,在讨论内存操作正确性的时候,通常分为两个部分:memory consistency 和 cache coherence[3]。
本节着重讨论cache coherence的实现。
2.1 cache vs buffer
在底层系统设计中通常会有cache 及 buffer的设计,两者都有缓存的意思,那么真正的区别在哪里呢,知乎上有个回答我感觉挺好的。Cache 和 Buffer 都是缓存,主要区别是什么?
Buffer(缓冲区)是系统两端处理**速度平衡**(从长时间尺度上看)时使用的。它的引入是为了减小短期内突发I/O的影响,起到**流量整形**的作用。比如生产者——消费者问题,他们产生和消耗资源的速度大体接近,加一个buffer可以抵消掉资源刚产生/消耗时的突然变化。 Cache(缓存)则是系统两端处理**速度不匹配**时的一种**折衷策略**。因为CPU和memory之间的速度差异越来越大,所以人们充分利用数据的局部性(locality)特征,通过使用存储系统分级(memory hierarchy)的策略来减小这种差异带来的影响。
2.2 cache设计
从cache vs buffer的区别中我们可看出,cache的出现其实就是为了缓解CPU与主存之间的速度极度不平衡。因此通常CPU设计中引入了cache,分为L1 cache,L2 cache和L3 cache,其性能指数大致如下[11]:
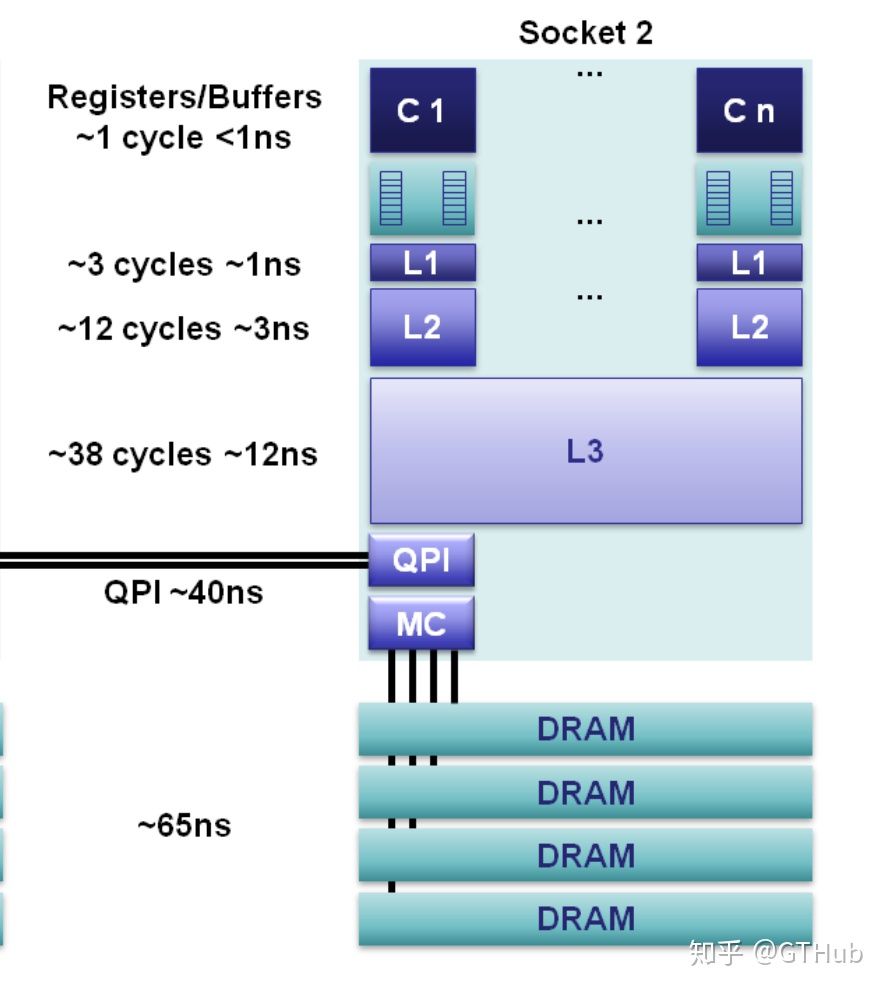
通常L1 cache又会分为I cache和D cache,分别存放指令与数据,L1 cache通常是core独占的,L2可以是两个core共享,L3 cache则是所有core共享。
2.2.0 CPU cache架构
如下图[4], 目前的CPU架构中的cache通常架构如此,这里的cache是L1 cache。我们这里讨论的cache基本都是基于L1 cache的,因为L1 cache通常是core独占的,所以L1 cache的设计及数据一致性是难点也是重点。
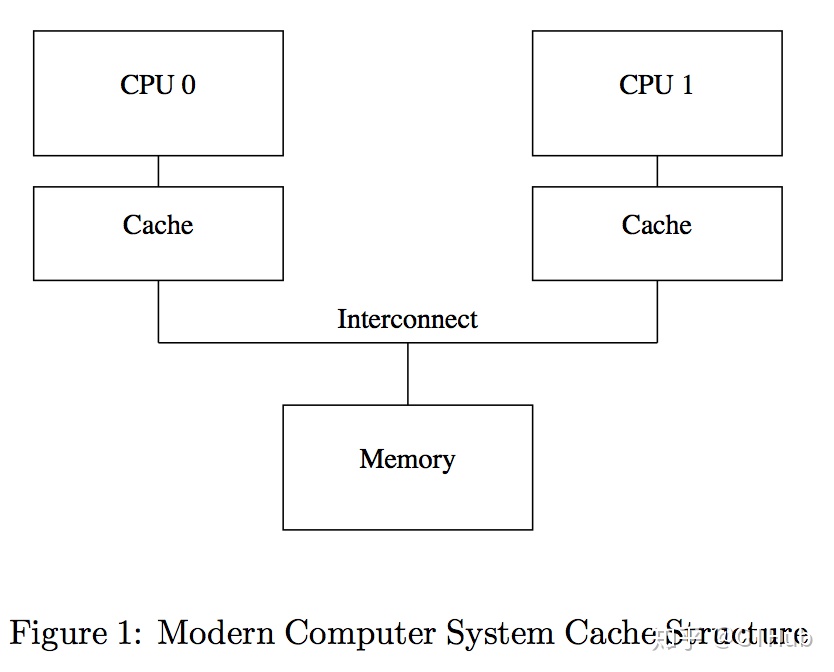
cache**中的数据存放单位是**cache line,通常一个**cache line**长度大概在16-256Bytes之间。CPU访问memory的时候首先会先查看cache中是否已经缓存该address,如果已缓存当前address并且是可用的,那么CPU就会直接从cache读取该值,这样极大的提高performance。如果所要访问的address不在cache中,CPU则要从memory读取,CPU会读取cache line大小的数据,并将其放入cache中这样下次读取的时候可以直接从cache中读。L1 cache通常在32KB大小,当cache被填满之后就需要按照一定策略将元素踢出去,这个策略可以是**LRU**或者**随机**等等。
NOTE: 这让我想到了virtual memory的page swap
这里有两个小点需要注意:
1、L1 cache独占导致的数据不一致 因为每个core都有自己独立的L1 cache,对于一个共享的memory location两个cache可以有自己的copy。那么这就会出现了数据不一致的状况,两个core可能同时访问这个memory location,且如果一个core是对这个memory location进行修改,那么这就需要两边的cache进行同步,防止数据不一致。这个工作就是**cache coherence protocol**要做的事情。
2、cacheline导致的false sharing
struct test {
uint32_t a;
uint32_t b;
}
test t;
t是一个共享变量,core1上线程t1访问t.a, core2线程t2访问t.b,如果cacheline大小是16Bytes,那么当t1访问t.a时cache miss,然后会将这个t.a读取到cache中,但是为了提高效率,core每次读取的长度是cacheline的长度,t.a长度是4, t.b长度是4,所以在一次读取中会将t.a和t.b一次性读到了自己cache中了,那么t2也同样存在这个问题,如果t1修改当前cacheline中的值,他需要与core2对应的cacheline同步,那么本来两个可以并发的memory location引入了不必要的同步。对性能产生不必要的影响。
NOTE: 上述问题和byte assignment 非常类似
那么为了避免false sharing,就需要让这两个memory location进行cacheline对齐。C++ 提供了alignas的方法。
2.3 cache coherence protocol
前面小节提到了为什么需要coherence protocol,那么coherence protocol是如何保证cache之间的数据一致性的呢?
这里就需要引入MESI协议了,MESI是一种维护cacheline状态一致性的协议。MESI: 由Modified,Exclusive,Share,Invalid四种状态组合。
2.3.1 cacheline state
1、Modified(M): 当一个core 的cacheline的状态是M时,说明当前core最近修改了这个cache,那么其他core的cache不能再修改当前cache line对应的memory location,除非该cache将这个修改同步到了memory。这个core对这个memory location可以理解为Owned。
NOTE: 其他core的cache如何知道"不能再修改当前cache line对应的memory location"?参见下面的share。
2、Exclusive(E):
NOTE: "exclusive"的意思是排他的、独有的,也就是说,这个cache中的memory location是独有的,其他的cache中都不包含;显然它和"share"是相反的
E这个状态与M很像,区别在于当前core并没有修改当前的cacheline,这意味着当前cacheline存储的memory location的值是最新的。当前core可以对该cacheline进行modify且不需要与其他core的cache同步。这个core对这个memory location可以理解为Owned。
3、Share(S): S表示当前cacheline在其他core的cache也存在copy,当前core如果需要修改该cacheline则需要与其他core的cache进行提前沟通。
4、Invalid(I): I表示当前cacheline是空的。
cacheline的状态变化需要在各个core之间同步,那么如何进行同步呢,MESI使用protocol message。
NOTE: 这让我想到了gossip protocol
2.3.2 protocol message
作为core之间的沟通工具,protocol message分为以下几种消息类型:
1、Read 当一个cache需要读取某个cacheline消息的时候就会发起read消息。
2、Read Response read response是read的回应,这response可以来自其他core的cache也可以来自memory。当其他core中对当前cacheline是M状态时,则会发起read response。
3、Invalidate Invalidate消息包含对应的memory location,接收到这个消息的cache需要将自己cacheline内容剔除,并响应。
4、Invalidate acknowledge 接收到Invalidate后删除cacheline中的数据就向发起者回复invalidate ack。
5、Read Invalidate 这个消息包含两个操作,read和invalidate,那么它也需要接收read response和多个invalidate ack响应。
6、write back writeback包含数据和地址,会将这个地址对应的数据刷到内存中。
NOTE: commit
2.4 store buffer and invalidate queue
MESI中的四种状态可以互相转化,具体状态迁移条件请参考[4],这里不再赘述。
2.4.1 store buffer
NOTE: 其实就是将write的值,放到缓存中
CPU设计者都是在极致压榨其性能。cache就是CPU设计者压榨CPU性能的一种体现,但是这样他们觉得还不够。考虑一种状况,假设当core1执行一次store操作,且这个store操作的memory location对应的cacheline在另外一个core2上是owned状态,那么core1需要向core2发送Invalidate message,并且需要等到core2返回invalidate ack之后才能继续向下执行,那么在这个期间core1就处于**盲等**阶段,那么core1必须要等这么久吗?于是CPU设计者引入了store buffer,这个buffer处于CPU与cache之间。如下图[4].
NOTE: core1执行了修改,因此其他的cache需要更新最新值;

有了store buffer之后core1如果执行store操作就不用立刻向core2发送invalidate message了,core1只需要将store值添加到store buffer中即可。但是引入store buffer会带来两个问题。
1、考虑以下场景:
// a, b init to 0.
a=1;
b = a + 1;
assert(b == 2);
上述代码中,core执行a=1后,a=1这个值被放到core的storebuffer里了,然后继续执行b=a+1,这时候core的cacheline中保存的a还是原来的0.这个时候就会导致assert失败。因为我们在storebuffer里和cacheline中的a是两个独立的拷贝,所以导致这种错误的结果,因此CPU设计者通过使用"store Forwarding"的方式解决这个问题,就是在执行load操作时先去storebuffer中查找对应的memory location,如果查到就使用storebuffer中的最新值。
2、考虑另外一个场景
void foo(void) {
a=1;
b=1;
}
void bar(void) {
while (b == 0) continue;
assert(a == 1);
}
foo和bar两个函数如果在两个不同的core上执行,假设core1执行foo,core2执行bar,a不在core1的cache中,b在core1的cache中,且b对应的cacheline状态是M。
NOTE: 两个thread分别执行foo、bar
那么core1执行a=1的时候会将a=1放到storebuffer中,然后再执行b=1,因为b在core1上是M状态,所以修改b不需要与其他core进行同步,b的修改直接就在cacheline中进行了,所以也不会进storebuffer。这时候core2执行while(b==0)判断的时候发现b=1了,那么就会进入到assert,但这个时候如果a=1的storebuffer还没有更新core1中的a的cacheline的话,core2获得的a的值为0,那么这个时候结果也是不符合预期的。
NOTE: a不是core1 owner的,因此需要进入store buffer
但是在CPU设计层面是无法判断当前core中执行的变量是否与其他的core中的变量存在关系,因为CPU在执行代码的时候他认为这个当前所执行程序就是一个单线程的,他无法感知多线程的存在。因此这个问题无法在CPU设计层面解决,这个就需要编码人员介入了,编码人员需要告诉CPU现在需要将storebuffer flush到cache里,于是CPU设计者提供了叫**memory barrier**的工具。
void foo(void) {
a=1;
smp_mb(); // memory barrier
b=1;
}
void bar(void) {
while (b == 0) continue;
assert(a == 1);
}
smp_mb()会在执行的时候将storebuffer中的数据全部刷进cache。这样assert就会执行成功了。
2.4.2 invalidate message queue
storebuffer帮助core在进行store操作的时候尽快返回,这里的buffer和cache都是硬件元素,所以这些buffer一般都比较小(或许就只有几十个字节这么大),当storebuffer满了之后就需要将buffer中的内容刷到cache,刷到cache就会触发cacheline的invalidate message,这些message会一起发送给其他的core,然后等到其他的core返回invalidate ack之后才能继续向下执行。那么这个时候问题又来了,这些message发到另外的core,这些core需要先invlidate,然后在返回ack,如果这些core本来就很忙的话就会导致message处理被延后,这对于CPU设计者来说同样是不可接受的。因此CPU设计者又引入了invalidate queue。如下图[4].
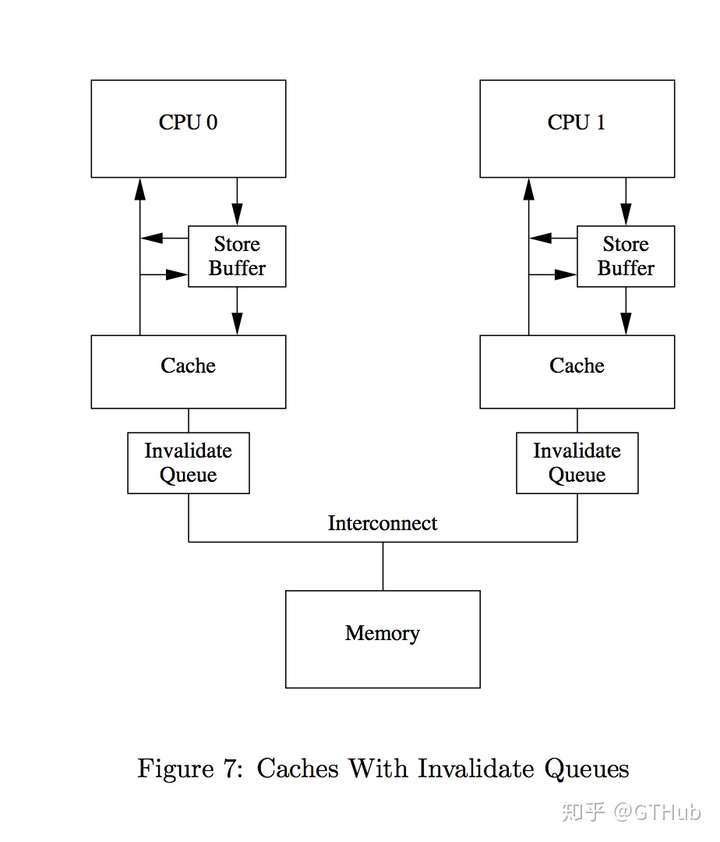
同样,类似于storebuffer,有了invalidate queue之后,发送的invalidate message只需要push到对应core的invalidate queue即可,然后这个core就会返回对应的invalidate ack了,中间不需要等待。这样cache之间的沟通就不会有很大的阻塞了,但是这同样带来了问题。
1、考虑以下场景 这个例子与store buffer中的例子一样。
void foo(void) {
a=1;
smp_mb(); // memory barrier
b=1;
}
void bar(void) {
while (b == 0) continue;
assert(a == 1);
}
core1执行foo,core2执行bar,同样当core1执行到smp_mb()会将storebuffer中的数据全部刷到cache,然后cache会向core2发送invalidate message,这个message会push到core2的invalidate queue, 然后执行b=1之后,core2的bar判断b==0失败然后执行assert,但是这时候如果core2中a的cacheline不为I,且invalidate queue还没有刷到core2的cache,这时候assert还会失败。这也是不符合程序语意的。但是同样core2并不知道当前执行的a与其他core中的变量有什么关系,CPU设计层面依然不能直接解决这个问题。于是还是需要加上memory_barrier.
void foo(void) {
a=1;
smp_mb(); // memory barrier
b=1;
}
void bar(void) {
while (b == 0) continue;
smp_mb(); // memory_barrier
assert(a == 1);
}
同样,在core2中添加smp_mb(),这个memory_barrier会将所在core的storebuffer和invalidate queue都 flush。
2.5 memory barrier
上面两小节中可已看出memory barrier的作用,上面提到的smp_mb()是一种full memory barrier,他会将store buffer和invalidate queue都flush一遍。但是就像上面例子中体现的那样有时候我们不用两个都flush,于是硬件设计者引入了**read memory barrier**和**write memory barrier**。
read memory barrier会将invalidate queue flush。
write memory barrier会将storebuffer flush。
NOTE: 为什么叫做read、write?
write是指将storebuffer中的内容write到 cache中
read是指cache读取invalid queue 中的内容,其实联系上述图就可以知道
2.6 总结
从上几节讨论可以看出,cache coherence主要集中在对一个memory location的一致性保证,MESI协议是对同一个memory location在不同cache之间的一致性保证。
3 memory consistency[3]
memory model, memory model consistency, memory consistency三个指的是同一个东西。
memory consistency是什么[8]: \1. The guarantees provided by the runtime environment to a multithreaded program, regarding the order of memory operations. \2. Each level of the environment might have a different memory model – CPU, virtual machine, language. \3. The correctness of parallel algorithms depends on the memory model.
这节我们讨论的是CPU memory model。
3.1 consistency分类
一致性从强到弱有多种分类,分布式系统中常用lineraziblity consistency(线性一致性),这是一种强一致性模型,在对分布式事务的一致性保证中又有**Serializability** consistency这也是一种强一致性模型,在底层系统设计时又有sequence consistency(SC)一致性模型,sequence consistency也是一种强一致性模型,不过比线性一致性稍弱。当然还有若一致性模型,比如内存一致性中的relaxed memory consistency model。
在底层系统设计时,一致性设计主要是在SC和XC的一种设计,为什么在底层系统设计时不是对lineraziblity consistency的实现而是对相比较较弱的SC或者XC的实现?这个在本节末尾会谈一下个人的观点。
本文主要是对memory consistency的一致性模型的总结,所以对lineraziblity和**Serializability** consistency不会涉及很多。
3.2 Sequence Consistency
3.2.0 reorder
在谈memory consistency之前我们先了解下reorder,我们编码并发布运行需要经过编译器编译后然后在CPU上运行,通常我们认为我们所写的代码是按照顺序执行下去的,就是说上一个语句一定在下一个语句执行之前执行。这是我们的潜意识,然而事实可能并不是这样,因为中间经过了编译器也经过了CPU。编译器和CPU为了充分提高程序运行性能会在内部进行一系列优化,这些优化方法有很多,也很复杂。比较典型的有reorder,Speculative execution等。编译器会对我们写的代码顺序进行reorder,CPU执行的时候也会进行reorder,也就是说在执行时,我们写的代码并不是一定按照我们所看到顺序。但是不用担心,CPU或者编译器在reorder的时候并不会无厘头的reorder,他们至少要保证的是,在reorder之后,程序所表现出来的行为效果与单线程执行效果是一致的。这里提到的是单线程,也就是说CPU和编译器并不能感知道你的代码是多线程还是单线程,他只能保证单线程状况时正确的,多线程就不得而知了。
所以 *C++ and the Perils of Double-Checked Locking.*这篇论文的作者有这么一句话:"Multithreading is just one damn thing after, before, or simultaneous with another. "。 其实蛮有道理的。
那么既然CPU和compiler不能感知**多线程**,那会出现什么问题呢?如下。
NOTE: 无法进行control
3.2.1 memory consistency motivation
在memory 系统设计时为什么需要memory consistency这样的约束?考虑下面表格锁描述的一种场景。
core C1与 core C2是两个单独的core,各自执行自己的程序,就像表格标题r2会一直被置为NEW吗?答案当然不是,首先CPU是存在out-of-order[6]优化的,另外对于core来说,他并不知道自己当前执行的是一个多线程程序。一个CPU core在设计时至少需要保证当前core上执行的程序是遵循其program order的(program order就是代码顺序)。但是为了提高性能,CPU优化引入了out-of-order-excution机制和Speculative execution机制,那么对于C1而言,CPU可以执行S2->S1,也可以执行S1->S2, 对于这两种执行方式在C1看来是没有问题的,因为单线程而言这两种执行方式最后达到的效果是一样的。(因为S2和S1是对不同的memory location的操作,所以会reorder,如果是对同一个memory location操作是不允许出现这种reorder的,当然TSO允许这种reorder,但是对同一location而言reorder前后效果一致,具体会在后面章节详细描述。)
NOTE: 关于TSO,参见 wikipedia Memory ordering:
TSO
Total store order (default)
那么如果C1的执行顺序是S2->L1->L2->S1,那么得到的结果r2 = 0,而不是向我们预期的r2 = NEW。对我们而言这种结果是超出预期的,是错的。

那么为了保证不会出现这种超出预期的行为,我们就需要一种规则来约束这种行为不能出现。这个任务就是memory consistency需要保证的(这里指的是强一致性模型:SC(sequence consistency)/TSO, XC的memory consistency并不能保证这点)。
3.2.2 program order vs memory order
在引入SC定义之前,我们先明确什么是program order什么是memory order。这里我们谈的都是针对共享内存的操作,对那些局部变量,对core来说是私有的,不存在共享,所以不会存在consistency的问题。
NOTE: shared data
program order: 就是我们写的代码的顺序,这个是静态的也是每个CPU core各自拥有的。
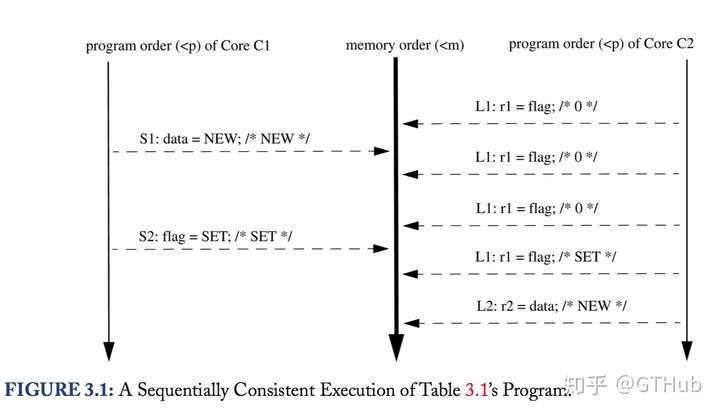
memory order: 就是代码执行的顺序,这个是全局的,每个CPU core对共享内存的执行都会出现在memory order中。
如下图所示,每个core的代码都会对应到memory order这条执行线上。
3.2.3 SC definition
Lamport引入了对SC的定义,他这样定义multiprocessor下的SC: "the result of any execution is the same as if the operations of all processors (cores) were executed in some sequential order, and the operations of each individual processor (core) appear in this sequence in the order specified by its program."[3]
如上图中,S1 与 S2的program order可以表示为: S1 <p S2, S1与L2可以表示为 S1 <m L2.
用<p 表示program order的先于顺序,<m表示memory order的先于顺序。
那么SC的形式化定义如下[3]:
(1) All cores insert their loads and stores into the order <m respecting their program order, regardless of whether they are to the same or different addresses (i.e., a=b or a≠b). There are four cases:
If L(a) <p L(b) ⇒ L(a) <m L(b) /* Load→Load */
If L(a) <p S(b) ⇒ L(a) <m S(b) /* Load→Store */
***If S(a) <p S(b) ⇒ S(a) <m S(b) /* Store→Store */**
***If S(a) <p L(b) ⇒ S(a) <m L(b) /* Store→Load */**
(所有对共享内存的操作都可以抽象成load(读取)和store(写入),每一core执行load和store是按照其program order,那么就有S1 <p S2肯定会推出 S1 <m S2,SC的定义也由此引入了load和store的四种关系。在SC的定义中这四种关系是不允许被reorder的,即使是对不同memory location的操作。)
(2) Every load gets its value from the last store before it (in global memory order) to the same address:
Value of L(a) = Value of MAX <m {S(a) | S(a) <m L(a)}, where MAX <m denotes “latest in memory order.”
(SC中定义每个共享内存的读取肯定是其在memory order中最近的一次写入的值)。
只要符合上述两个条件,那么我们就可以说这个memory操作是符合顺序一致性的。
下表给出了SC的定义中约束的行为。operation1 <p operation2。
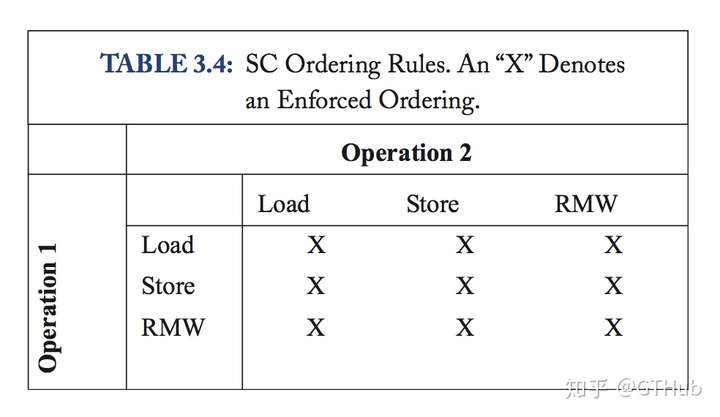
3.2.4 SC example
还是用3.2.1节中的例子,来验证一下SC对memory操作的约束。
- 程序memory operation如下

- 程序可能出现的SC执行结果 下图中前三种结果是符合SC定义的,最后一种是不符合SC定义的,另外一方面可以看出SC中是不允许执行线(虚线)交叉的。每个执行语句落在memory order这条线上的位置表示当前的执行已经发生了。(在lineraziblity consistency定义中每个操作会划分为invocation和response两个阶段,且操作会在这两个阶段中间任一个瞬间发生,这里语句在memory order这条线上的落点就是该操作执行的瞬间。)
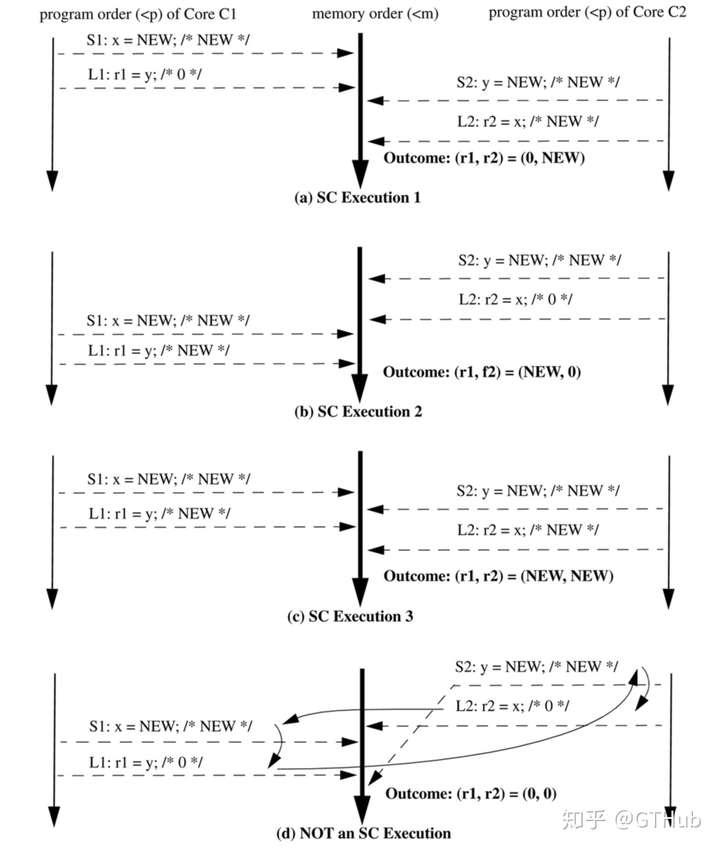
从图中可以看出在保证program order不变的情况下,memory order的顺序可以随意排列。这个特别像我们平常洗牌的过程,两副扑克牌互相交叠,但是每副牌的顺序(program order)是不变的,但是在洗完之后两副牌合成一副牌的时候这个顺序是随机的,不确定。 在符合SC定义下的执行中会出现多种正确的结果,这些结果符合SC定义,在编码人员开来,这样一个多线程程序执行的结果也是正确的。并发在不强加干涉的情况下是不能预测执行顺序的。
3.3 TSO
3.3.0 SC带来的问题
SC严格定义了对于共享内存的load和store操作,loadload,storestore,loadstore,storeload四种执行顺序是不允许reorder的。当下CPU的执行速度已经甩DRAM(memory)好几个量级,如果每次store,load操作都从DRAM读取会拖慢CPU的执行速度,在这个极度压榨硬件性能的时代,是不能接受这种行为的。因此在x86的架构实现中引入了TSO。
However, current commercial compilers and most current commercial hardware do not preserve sequential consistency.[9]
3.3.1 TSO如何解决SC的问题
TSO全称Total Store Order,我们在讨论TSO的时候先忽略cache这一层。
TSO在CPU与memory之间引入了write buffer。CPU写入的时候先写入write buffer然后就返回了,这样就将cpu与memory之间的差距隐藏了,但是这样同样带来了一个问题。

还是上面这个例子,S1将x=NEW放到了core C1的write buffer中,S2将y=NEW放到了C2的write buffer中,那么在执行L1,L2的时候,r1与r2这时候从memory读到是0。这个是违背了SC的,但是这样的设计确实带来了性能的提升。
那么在TSO模型下的执行结果如下:
前三种与SC一致,第四个执行结果则是TSO独有的,可以看出,TSO中允许执行线交叉。
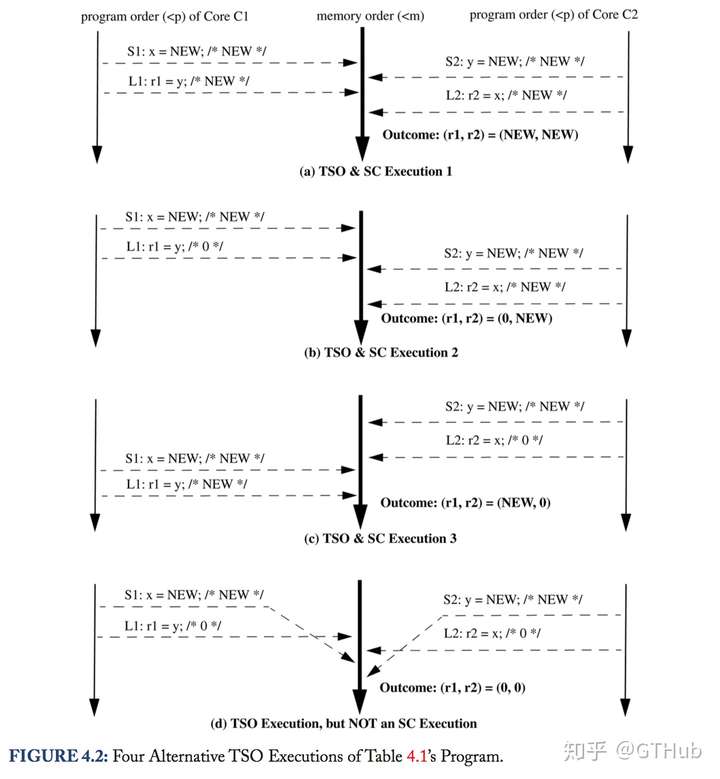
3.3.2 TSO definition
TSO在实现SC的过程中做了一些改动,带来了性能提升。SC是TSO的一些特例,x86通过在每个core上引入FIFO 的write buffer实现了TSO[3]。
TSO与SC的定义很像,其定义如下:
(1) All cores insert their loads and stores into the memory order <m respecting their program order, regardless of whether they are to the same or different addresses (i.e., a==b or a!=b). There are four cases:
If L(a) <p L(b) ⇒ L(a) <m L(b) /* Load→Load */
If L(a) <p S(b) ⇒ L(a) <m S(b) /* Load→Store */
If S(a) <p S(b) ⇒ S(a) <m S(b) /* Store→Store */
// If S(a) S(a)
(2)Every load gets its value from the last store before it to the same address:
// Value of L(a) = Value of MAX <m {S(a) | S(a) <m L(a)} *// 这个是SC的, TSO没有*
Value of L(a) = Value of MAX <m {S(a) | S(a) <m L(a) or S(a) <p L(a)}
TSO的定义与SC的定义有两个变化:
- 变化一:不保证storeload顺序 举个例子:Core C1中S1和L1, S1先去L1执行,但是S1只是将值送入了write buffer就返回了,紧接着执行L1,L1在memory order中的点执行完之后,S1的write buffer这时候flush到内存,那么S1在memory order这条线上真正执行的点在L1之后了,那么这时候S1与L1就出现了reorder了。
- 变化二:load的最新值不一定是memory order中最近的,有可能是program order最近的store 需要注意的是,无论是TSO还是SC都需要至少保证一点,即使允许reorder也要保证program执行的结果与单线程执行的结果是一致的。比如一对操作: S1: x = new L1: y = x. 无论是TSO还是SC都需要保证y读到的是x=new的值(排除其他线程在这两个语句之前对x进行store操作。) 因为TSO引入了write buffer,那么上述x=new会写入buffer,如何确保L1会读到最新的值呢,TSO引入了一种叫“bypass”的概念,就是对于**同一memory location**的读写会保障load会读到store的最新值无论这个store会不会进入write buffer。 如下图所示: L1读取的是S1的值,即使L1 <m S1 且 S1 <p L1.
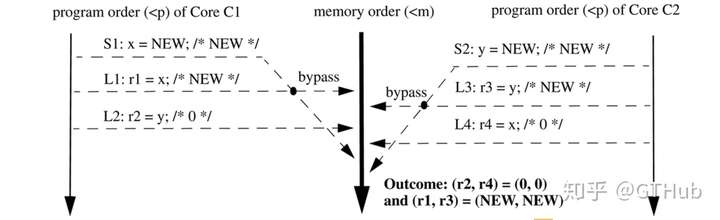
3.3.3 FENCE
3.3.1小节提到的例子中,出现了一种超出预期的执行状况,如果我们想避免这种问题,那么需要在上层代码中添加FENCE,这个fence可以理解为memory barrier,他的作用是将write buffer中的记录flush到内存。
FENCE会强制保证program order。
- If S(a) <p FENCE ⇒ S(a) <m FENCE /* Store → FENCE */
- If FENCE <p L(a) ⇒ FENCE <m L(a) /* FENCE → Load */
如果再S1与L1之间加上FENCE,就保证了S1 <p L1 和 S1 <m L1.
x86系统中并没有为我们加上FENCE,什么时候需要添加FENCE只有开发人员知道,所以为了避免程序出现莫名其妙的错误,记得在store和load共享内存的时候加上FENCE。
因此TSO下的operation order如下: (operation1 <p operation2)

3.4 relaxed memory consistency
SC和TSO严格意义上来说都是一种强一致性模型,因为他们都对程序的执行顺序做了一定的约束,既然存在约束那么就会带来一定的性能损耗。
那么有没有一种没这么多的约束的一致性模型,能够使机器进行深度的优化并发挥极致性能。那么执行顺序的正确性就只能有编码人员来保证了。
relaxed memory consistency实现对于load与store顺序完全放开,除了对同一memory location的操作保证load看到是最新的store以外其他都不进行约束,编码人员如果想强加order可以通过上述的FENCE。
3.5 Linearizability consistency
**Linearizability**是比SC更强的一致性模型,在SC定义中不同core的执行语句在memory order的时间线中可以随意插入,而对于Linearizability consistency不仅限制了单线程中的执行顺序,同时对于多线程中执行顺序也做了一些限制。具体 Linearizability consistency的相关知识在后面文章再详细总结一下。
3.6 memory consistency总结
1、为什么memory consistency只谈sequence consistency(SC)而不谈linearizability(LIN)
-
- 一方面,因为SC在底层已经定义一个多线程能够对共享内存并发操作的正确性,LIN比SC更严格,LIN是SC的一种形式,LIN更贴近与上层,在SC提供的多种正确性的执行序列中,我们需要一个符合我们业务逻辑正确性的保障手段,而LIN就是这种手段。
- 另一方面是,在底层系统中CPU和编译器是不能意识到多线程的存在的,也就是说CPU只是 知道当前的指令,并不知道当前指令与其他CPU指令之间的关系,LIN中约束了两个process(也就是两个执行体,可以理解为线程也可以理解为进程等)之间的partial order(偏序关系),而这种关系在底层是不得而知的。
- 在一个原因,LIN的成本更高,如果再CPU层面实现LIN,那么原本用来提高性能的cache和store buffer的作用就会被大大削弱,所以在能够保证正确性的基础上又能充分利用CPU资源的前提下,LIN并没有在CPU层面实现。
**SC**在定义中没有约定执行时间这个概念,只是强调了program order与execution order,也就是memory order。 **Linearizability**在定义中约定了两个执行体之间的执行顺序,也就是执行时间先后被约定了。
2、memory consistency与cache coherence的关系 从以上讨论可以看出,memory consistency注重的是全局的memory order,而cache coherence则是关注于一个memory location。 memory consistency是保证多处理器编程中的正确性,我们在讨论这个的时候可以把cache当做一个黑盒子来处理,也就是说即使没有cache,我们也同样需要memory consistency来保证正确性。
3、memory barrier与memory order的关系 第2节中最后提到了memory barrier,这个memory barrier会flush storebuffer和invalidate queue。那么memory barrier与memory order有啥关系呢。 memory order是全局的多处理器对共享变量的操作的一个排序。对共享变量操作落在memory order这条线上的点就是对外表现出的执行顺序。 memory barrier会将storebuffer中的内容flush到cache然后cache,那么只有执行这个memory barrier之后,这个操作才算真正的执行,才能真正落在memory order这条线上。所以memory barrier起到一个order的作用,这个order是一个动词,就是什么时候真正执行这个动作。
4 篇幅限制,后续部分放在后一篇
7 References
- M. Mizuno, M. Raynal, J.Z. Zhou. Sequential Consistency in Distributed Systems.
- Scott Meyers and Andrei Alexandrescu. C++ and the Perils of Double-Checked Locking.
- Daniel J. Sorin, Mark D. Hill, and David A. Wood. A Primer on Memory Consistency and Cache Coherence.
- Paul E. McKenney .Memory Barriers: a Hardware View for Software Hackers.
- C++ memory order
- out of order execution
- The New C++: Lay down your guns, knives, and clubs
- c++ memory model
- H. Boehm, S. V. Adve.Foundations of the C++ Concurrency Memory Model
- C++ Standard - 2012-01-16 - Working Draft (N3337).pdf
- CPU Cache and Memory Ordering
- think cell talk memory model
- Acquire and Release Semantics
- C++ Memory model