aliyun 深入解析redis cluster gossip机制
社区版redis cluster是一个P2P无中心节点的集群架构,依靠gossip协议传播协同自动化修复集群的状态。本文将深入redis cluster gossip协议的细节,剖析redis cluster gossip协议机制如何运转。
协议解析
cluster gossip协议定义在在ClusterMsg这个结构中,源码如下:
typedef struct {
char sig[4]; /* Signature "RCmb" (Redis Cluster message bus). */
uint32_t totlen; /* Total length of this message */
uint16_t ver; /* Protocol version, currently set to 1. */
uint16_t port; /* TCP base port number. */
uint16_t type; /* Message type */
uint16_t count; /* Only used for some kind of messages. */
uint64_t currentEpoch; /* The epoch accordingly to the sending node. */
uint64_t configEpoch; /* The config epoch if it's a master, or the last
epoch advertised by its master if it is a
slave. */
uint64_t offset; /* Master replication offset if node is a master or
processed replication offset if node is a slave. */
char sender[CLUSTER_NAMELEN]; /* Name of the sender node */
unsigned char myslots[CLUSTER_SLOTS/8];
char slaveof[CLUSTER_NAMELEN];
char myip[NET_IP_STR_LEN]; /* Sender IP, if not all zeroed. */
char notused1[34]; /* 34 bytes reserved for future usage. */
uint16_t cport; /* Sender TCP cluster bus port */
uint16_t flags; /* Sender node flags */
unsigned char state; /* Cluster state from the POV of the sender */
unsigned char mflags[3]; /* Message flags: CLUSTERMSG_FLAG[012]_... */
union clusterMsgData data;
} clusterMsg;
可以对此结构将消息分为三部分:
1、sender的基本信息:
sender: node name
configEpoch:每个master节点都有一个唯一的configEpoch做标志,如果和其他master节点冲突,会强制自增使本节点在集群中唯一
slaveof:master信息,假如本节点是slave节点的话,协议带有master信息
offset:主从复制的偏移
flags:本节点当前的状态,比如 CLUSTER_NODE_HANDSHAKE、CLUSTER_NODE_MEET
mflags:本条消息的类型,目前只有两类:CLUSTERMSG_FLAG0_PAUSED、CLUSTERMSG_FLAG0_FORCEACK
myslots:本节点负责的slots信息
port:
cport:
ip:
2、集群视图的基本信息:
currentEpoch:表示本节点当前记录的整个集群的统一的epoch,用来决策选举投票等,与configEpoch不同的是:configEpoch表示的是master节点的唯一标志,currentEpoch是集群的唯一标志。
3、具体的消息,对应clsuterMsgData结构中的数据:
**ping、pong、meet:clusterMsgDataGossip,**这个协议将sender节点中保存的集群所有节点的信息都发送给对端,节点个数在clusterMsg的字段count中定义,这个协议包含其他节点的信息的字段有:
- nodename:
- ping_sent:最近一次sender节点给该节点发送ping的时间点。收到pong回复后ping_sent会被赋值为0
这里作者用了一个技巧去减少gossip通信带宽。
如果receiver节点上关于该节点的ping_sent=0 并且没有任何节点正在failover&该节点没有fail&receiver节点上关于该节点的pong_received<sender上的pong_received并且sender的pong_received大于receiver节点内核时间的500ms内,则将receiver节点关于该节点的pong_received时间设置为和sender节点一致,复用sender节点的pong_received。那么received节点则会减少对该节点发送ping。参考issue:https://github.com/antirez/redis/issues/3929
- pong_received:最近一次sender节点收到该节点发送pong的时间点
- ip:
- port:
- cport:
- flags:对应clusterMsg的flags,只不过存储的其他节点的
**fail:clusterMsgDataFail,**只有一个表示fail节点的nodename字段, 统计超过一半以上节点任务node pfail后发送fail msg
publish:clusterMsgDataPublish,集群间同步publish信息,以支持客户端在任一节点发送pub/sub
update:clusterMsgDataUpdate,当receiver节点发现sender节点的configepoch低于本节点的时候,会给sender节点发送一个update消息通知sender节点更新状态,包含:
- configEpoch:receiver节点中保存的sender节点的configepoch
- nodename:receiver节点中保存的sender节点的nodename
- slots:receiver节点中保存的sender节点的slots列表
运转机制
通过gossip协议,cluster可以提供集群间状态同步更新、选举自助failover等重要的集群功能。
握手联结
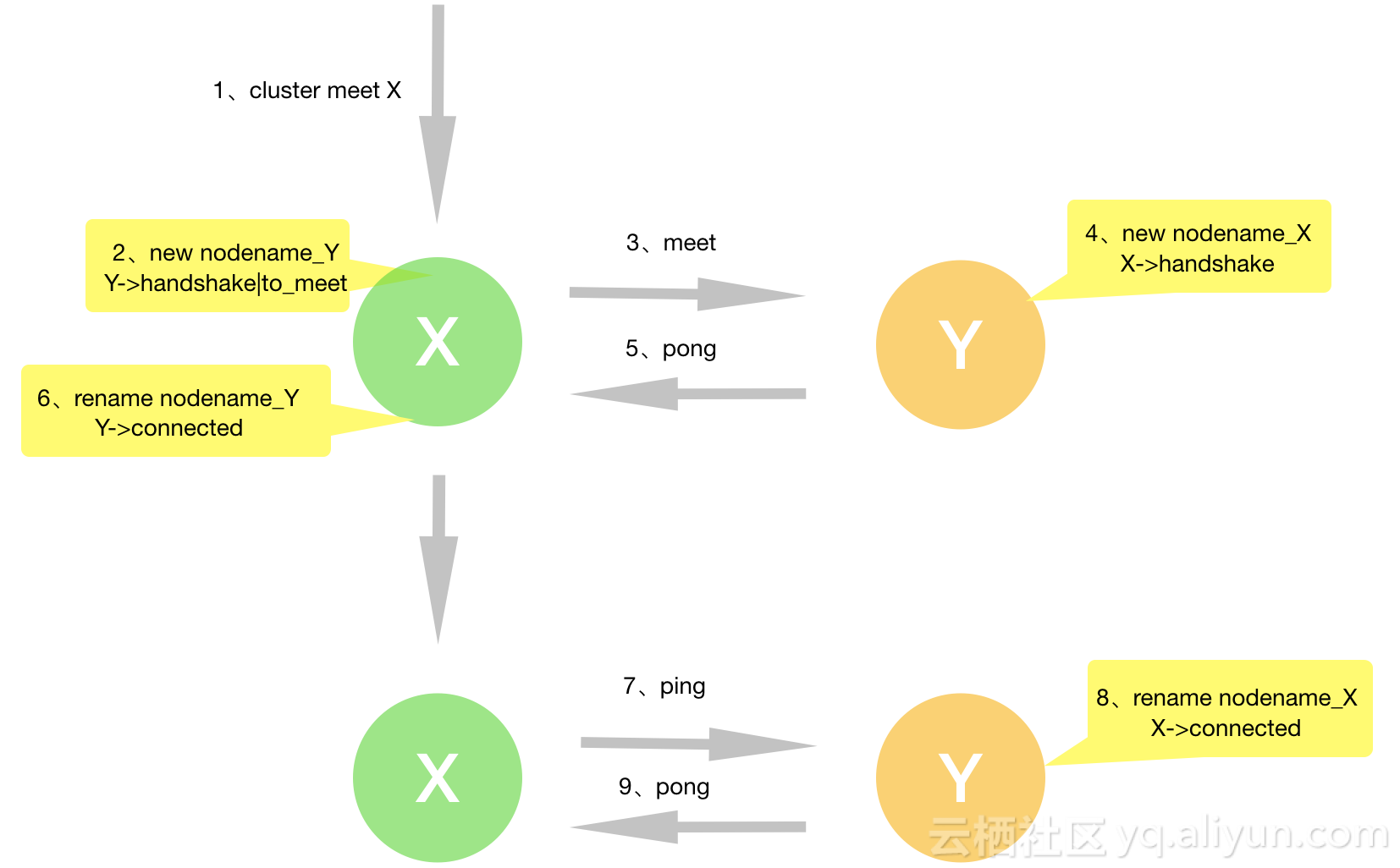
客户端给节点X发送cluster meet 节点Y的请求后,节点X之后就会尝试主从和节点Y建立连接。此时在节点X中保存节点Y的状态是:
- CLUSTER_NODE_HANDSHAKE:表示节点Y正处于握手状态,只有收到来自节点Y的ping、pong、meet其中一种消息后该状态才会被清除
- CLUSTER_NODE_MEET:表示还未给节点
Y发送meet消息,一旦发送该状态清除,不管是否成功
以下是meet过程:
(0)节点X通过getRandomHexChars这个函数给节点Y随机生成nodename
(1)节点X 在clusterCron运转时会从cluster->nodes列表中获取未建立tcp连接,如未发送过meet,发送CLUSTERMSG_TYPE_MEET,节点Y收到meet消息后:
(2)查看节点X还未建立握手成功,比较sender发送过来的消息,更新本地关于节点X的信息
(3)查看节点X在nodes不存在,添加X进nodes,随机给X取nodename。状态设置为CLUSTER_NODE_HANDSHAKE
(4)进入gossip处理这个gossip消息携带的集群其他节点的信息,给集群其他节点建立**握手**。
(5)给节点X发送CLUSTERMSG_TYPE_PONG,节点Y处理结束(注意此时节点Y的clusterReadHandler函数link->node为NULL)。
(6)节点X收到pong后,发现和节点Y正处在握手阶段,更新节点Y的地址和nodename,清除CLUSTER_NODE_HANDSHAKE状态。
(7)节点X在cron()函数中将给未建立连接的节点Y发送ping
(8)节点Y收到ping后给节点X发送pong
(9)节点X将保存的节点Y的状态CLUSTER_NODE_HANDSHAKE清除,更新一下nodename和地址,至此握手完成,两个节点都保存相同的nodename和信息。
看完整个握手过程后,我们尝试思考两个问题:
1、如果发送meet失败后,节点X的状态CLUSTER_NODE_MEET状态又被清除了,cluster会如何处理呢?
这时候节点Y在下一个clusterCron()函数中会直接给节点Y发送ping,但是不会将节点X存入cluster->nodes,导致节点X认为已经建立连接,然而节点Y并没有承认。在后面节点传播中,如果有其他节点持有节点X的信息并给节点Y发送ping,也会触发节点Y主动再去给节点X发送meet建立连接。
2、如果节点Y已经有存储节点X,但还是收到了节点X的meet请求,如何处理?
- nodename相同:
(1)节点Y发送pong给节点X
(2)如果正处于握手节点,会直接删除节点,这里会导致节点Y丢失了节点X的消息。相当于问题1。
(3)非握手阶段往下走正常的ping流程
- nodename不同:
(1)节点Y重新创建一个随机nodename放入nodes中并设置为握手阶段,此时有两个nodename存在。
(2)节点Y发送pong给节点X
(3)节点Y如果已经创建过和节点X的连接,节点Y会在本地更新节点X的nodename,删除第一个nodename存储的node,更新握手状态,此时只剩下第二个正确的nodename。
(4)节点Y如果没创建过和节点X的链接,会在clustercron()中再次给节点X发送ping请求,两个nodename会先后各发送一次。
(5)第一个nodename发送ping后,在收到节点X回复的pong中,更新节点X的nodename
(6)第二个nodename发送ping后,在收到节点X回复的pong中,发送节点X的nodename已经存在,第二个nodename处于握手状态,这时候直接删除了第二个nodename。
结论:只有nodename相同并且两个节点都在握手阶段,会导致其中一个节点丢掉另外一个节点。
健康检测及failover
详情见文章:https://yq.aliyun.com/articles/638627?utm_content=m_1000016044
状态更新及冲突解决
假如出现两个master的时候gossip协议是如何处理冲突的呢?
首先要理解两个重要的变量:
- configEpoch: 每个分片有唯一的epoch值,主备epoch应该一致
- currentEpoch:集群当前的epoch,=集群中最大分片的epoch
在ping包中会自带sender节点的slots信息和currentEpoch, configEpoch。
master节点收到来自slave节点后的处理流程:
(1)receiver比较sender的角色,
- 如果sender认为自己是master,但是在receiver被标记为slave,则receiver节点在集群视图中将sender标记为master。
- 如果sender认为自己是slave,但是在receiver被标记为master, 则在receiver的集群视图中将sender标记为slave, 加入到sender标记的master中,并且删除sender在reciver集群视图中的slots信息。
(2)比较sender自带的slot信息和receiver集群视图中的slots是否冲突,有冲突则进行下一步比较
(3)比较sender的configEpoch 是否 > receiver集群视图中的slots拥有者的configepoch,如是在clusterUpdateSlotsConfigWith函数中重新设置slots拥有者为sender,并且将旧slots拥有者设置为sender的slave,再比较本节点是有脏slot, 有则清除掉。
(4)比较sender自身的slots信息 < receiver集群视图中的slots拥有者的configepoch,发送update信息,通知sender更新,sender节点也会执行clusterUpdateSlotsConfigWith函数。
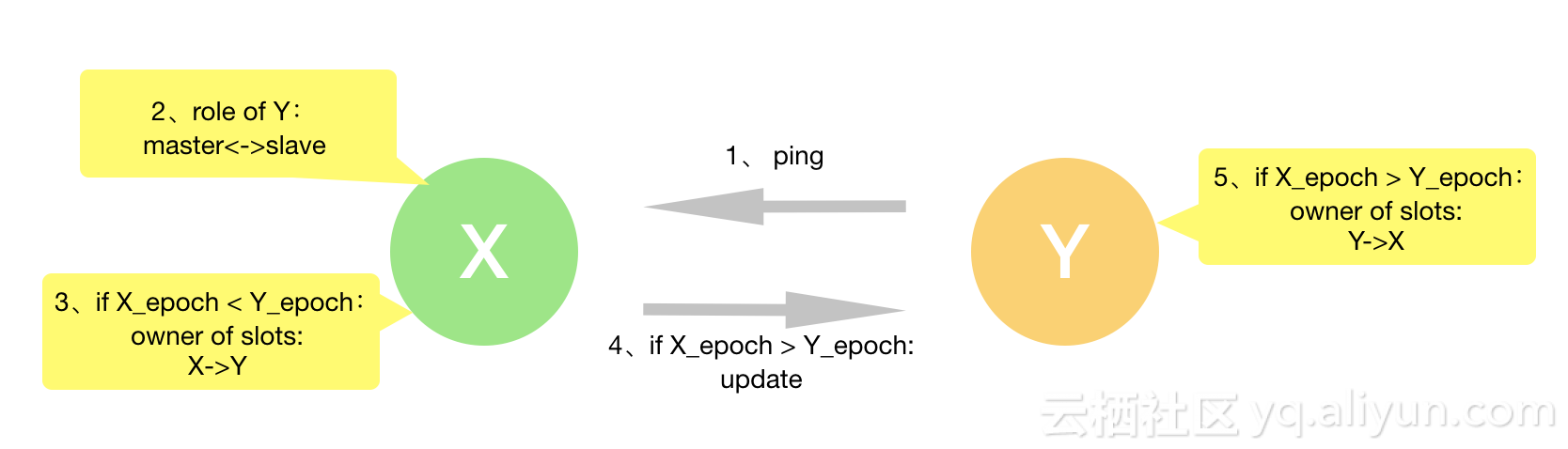
如果两个节点的configEpoch, currentEpoch,角色都是master, 这时候如何处理呢?
receiver的currentEpoch自增并且赋值给configEpoch,也就是强制自增来解决冲突。这时候因为configEpoch大,又可以走回上文的流程。
所以可能存在双master同时存在的情况,但是最终会挑选出新的master。
结束语
云数据库Redis版(ApsaraDB for Redis)是一种稳定可靠、性能卓越、可弹性伸缩的数据库服务。基于飞天分布式系统和全SSD盘高性能存储,支持主备版和集群版两套高可用架构。提供了全套的容灾切换、故障迁移、在线扩容、性能优化的数据库解决方案。欢迎各位购买使用:云数据库 Redis 版