关于本章
本章记录在阅读Natural Language Processing with Python的笔记。Natural Language Processing with Python是一本开源书籍,原书内容比较通俗易懂,可以作为入门NLP的读物。
在阅读的时候,我们应该选择性地去阅读,对于熟悉python的人,可以直接pass掉原书中关于python的内容。原书从chapter 5开始讲述NLP相关内容。
我觉得这本书的最大价值在于:
- 结合具体例子讲解了语言学中的的一些基础概念
- 给出了解决一些NLP task的Pipeline Architecture,读者可以参考进行实践,下面对此进行了总结。
读者需要注意的是,虽然书中给出了一些NLP task的实现方式,但是随着技术的进步,不断涌现出了解决这些已知的NLP task的新技术,所以不能够拘泥于书中的解决方式,而应该学习更加先进的解决方式。
内容概要
可以直接从chapter 5 Categorizing and Tagging Words 开始阅读;chapter 6 Learning to Classify Text讲文本分类;chapter 7 Extracting Information from Text讲如何从文本中抽取信息,其中给出的Information Extraction Architecture是比较具有启发意义的;chapter 8 Analyzing Sentence Structure其实讲述的是formal language中parsing的方法。
Pipeline Architecture
Simple Pipeline Architecture for a Spoken Dialogue System
在chapter 1. Language Processing and Python的5.5 Spoken Dialog Systems中给出了“Simple Pipeline Architecture for a Spoken Dialogue System”
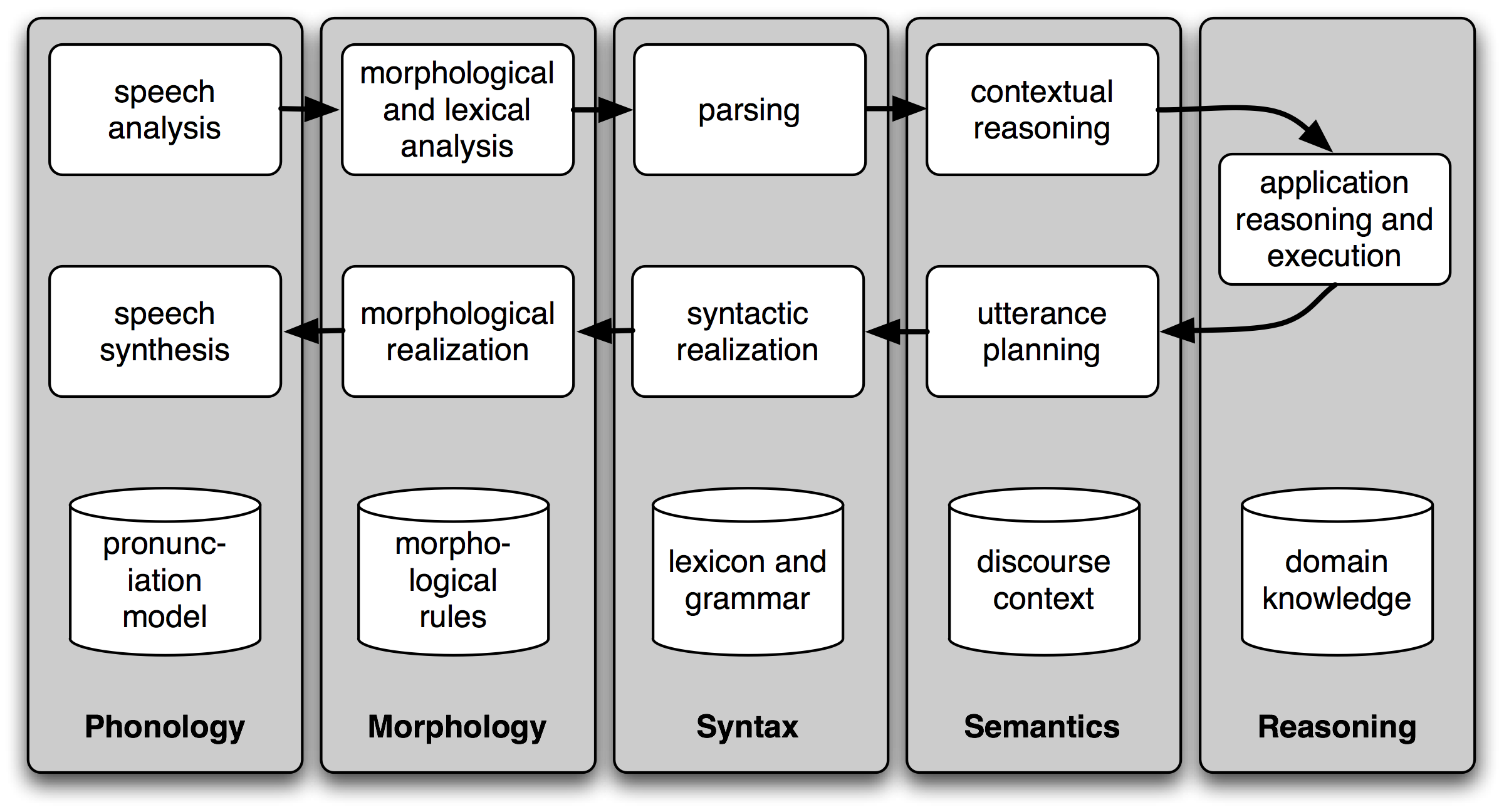
Figure 5.1: Simple Pipeline Architecture for a Spoken Dialogue System: Spoken input (top left) is analyzed, words are recognized, sentences are parsed and interpreted in context, application-specific actions take place (top right); a response is planned, realized as a syntactic structure, then to suitably inflected words, and finally to spoken output; different types of linguistic knowledge inform each stage of the process.