Symbolic and imperative
symbolic programming和imperative programming是当前DL领域的两种主流programming paradigm。
mxnet Deep Learning Programming Paradigm
Writing clear, intuitive deep learning code can be challenging, and the first thing any practitioner must deal with is the language syntax itself. Complicating matters, of the many deep learning libraries out there, each has its own approach to programming style.
复杂的问题是,在众多的深度学习库中,每个库都有自己的编程风格。
In this document, we focus on two of the most important high-level design decisions:
1) Whether to embrace(拥抱) the symbolic or imperative paradigm for mathematical computation.
NOTE: 关于symbolic programming,参见工程programming-language的
Theory\Programming-paradigm\Symbolic-programming章节
2) Whether to build networks with bigger (more abstract) or more atomic operations.
Throughout, we’ll focus on the programming models themselves. When programming style decisions may impact performance, we point this out, but we don’t dwell on specific implementation details.
NOTE: "dwell on"的意思是"思想局限于"
Symbolic vs. Imperative Programs
If you are a Python or C++ programmer, then you’re already familiar with imperative programs. Imperative-style programs perform computation as you run them. Most code you write in Python is imperative, as is the following NumPy snippet.
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
When the program executes c = b * a, it runs the actual numerical computation.
Symbolic programs are a bit different. With symbolic-style programs, we first define a (potentially complex) function abstractly. When defining the function, no actual numerical computation takes place. We define the abstract function in terms of placeholder values. Then we can compile the function, and evaluate it given real inputs. In the following example, we rewrite the imperative program from above as a symbolic-style program:
A = Variable('A')
B = Variable('B')
C = B * A
D = C + Constant(1)
# compiles the function
f = compile(D)
d = f(A=np.ones(10), B=np.ones(10)*2)
As you can see, in the symbolic version, when C = B * A is executed, no computation occurs. Instead, this operation generates a computation graph (also called a symbolic graph) that represents the computation. The following figure shows a computation graph to compute D.
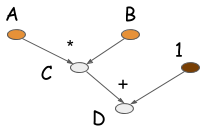
Most symbolic-style programs contain, either explicitly or implicitly, a compile step. This converts the computation graph into a function that we can later call. In the above example, numerical computation only occurs in the last line of code. The defining characteristic of symbolic programs is their clear separation between building the computation graph and executing it. For neural networks, we typically define the entire model as a single compute graph.
Deep learning libraries
Among other popular deep learning libraries, Torch, Chainer, and Minerva embrace the imperative style. Examples of symbolic-style deep learning libraries include Theano, CGT, and TensorFlow. We might also view libraries like CXXNet and Caffe, which rely on configuration files, as symbolic-style libraries. In this interpretation, we’d consider the content of the configuration file as defining the computation graph.
Now that you understand the difference between these two programming models, let’s compare the advantages of each.
Imperative Programs Tend to be More Flexible
When you’re using an imperative-style library from Python, you are writing in Python. Nearly anything that would be intuitive to write in Python, you could accelerate by calling down in the appropriate places to the imperative deep learning library. On the other hand, when you write a symbolic program, you may not have access to all the familiar Python constructs, like iteration. Consider the following imperative program, and think about how you can translate this into a symbolic program.
a = 2
b = a + 1
d = np.zeros(10)
for i in range(d):
d += np.zeros(10)
This wouldn’t be so easy if the Python for-loop weren’t supported by the symbolic API. When you write a symbolic program in Python, you’re not writing in Python. Instead, you’re writing in a domain-specific language (DSL) defined by the symbolic API. The symbolic APIs found in deep learning libraries are powerful DSLs that generate callable computation graphs for neural networks.
Symbolic Programs Tend to be More Efficient
As we’ve seen, imperative programs tend to be flexible and fit nicely into the programming flow of a host language. So you might wonder, why do so many deep learning libraries embrace the symbolic paradigm? The main reason is efficiency, both in terms of memory and speed. Let’s revisit our toy example from before.
NOTE: 关于host language和DSL的内容,参见
Theory\Programming-language\Host-language章节。
import numpy as np
a = np.ones(10)
b = np.ones(10) * 2
c = b * a
d = c + 1
Assume that each cell in the array occupies 8 bytes of memory. How much memory do you need to execute this program in the Python console?
As an imperative program we need to allocate memory at each line. That leaves us allocating 4 arrays of size 10. So we’ll need 4 * 10 * 8 = 320 bytes. On the other hand, if we built a computation graph, and knew in advance that we only needed d, we could reuse the memory originally allocated for intermediate values. For example, by performing computations in-place, we might recycle the bits allocated for b to store c. And we might recycle the bits allocated for c to store d. In the end we could cut our memory requirement in half, requiring just 2 * 10 * 8 = 160 bytes.
Symbolic programs are more restricted. When we call compile on D, we tell the system that only the value of d is needed. The intermediate values of the computation, in this case c, is then invisible to us.
We benefit because the symbolic programs can then safely reuse the memory for in-place computation. But on the other hand, if we later decide that we need to access c, we’re out of luck. So imperative programs are better prepared to encounter all possible demands. If we ran the imperative version of the code in a Python console, we could inspect any of the intermediate variables in the future.
Symbolic programs can also perform another kind of optimization, called operation folding. Returning to our toy example, the multiplication and addition operations can be folded into one operation, as shown in the following graph. If the computation runs on a GPU processor, one GPU kernel will be executed, instead of two. In fact, this is one way we hand-craft operations in optimized libraries, such as CXXNet and Caffe. Operation folding improves computation efficiency.
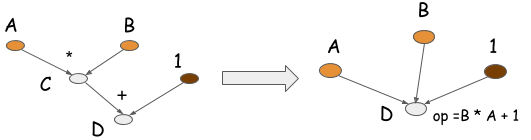
Note, you can’t perform operation folding in imperative programs, because the intermediate values might be referenced in the future. Operation folding is possible in symbolic programs because you get the entire computation graph, and a clear specification of which values will be needed and which are not.
Expression Template and Statically Typed Language
NOTE: 关于Expression Template ,参见工程programming language的
C-family-language\C++\Idiom\TMP\Expression-Template章节。