A
NOTE: 没有阅读
作者:Furion W 链接:https://www.zhihu.com/question/24301047/answer/83422523 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在此翻译和总结了3篇本引用文献中的部分内容,抛砖引玉。下文大致分三部分:
1、先介绍了内存系统coherence和consistency的行为表现, 并指出达成coherent的三个条件。
2、其次,将内存一致性模型分为顺序一致性模型(sequential consistency model)和松弛一致性模型(relaxed consistency model), 并讨论这两种模型的概念、实现与代价;
3、最后,讨论了原子操作间的关系(synchronized-with, happens-before等),浅析C++11内存模型,将其提供的6种内存次序归类成三种内存模型。
I. Memory coherence and memory consistency
[1] Chapter 5.2介绍了由共享内存(shared memory)的多核计算机因为使用缓存(cache)而引入的缓存连贯性(?)问题(cache coherence problem)。考虑下图:


图1. 针对单一内存地址的缓存一致性问题(引自[1] Figure 5.3)
图1描述的问题是:
1、处理器 A 缓存(读) X 的值 1;
2、处理器 B 缓存(读) X 的值 1;
3、处理器 A 直写(write through) X 的值为 0, 导致处理器 B 看到的(缓存中的) X 的值仍为旧值 1.
通俗地说,我们可以说一个内存系统是为Coherent, 如果任何一个对数据的**读操作**总是返回其最近被改**写**的值。这个模糊且过分简单的定义主要包含了内存系统两方面的行为表现:
1、Coherence定义了一个**读操作**能获得什么样的值。
2、Consitency定义了何时一个**写操作**的值会被**读操作**获得。
[1]中称,满足如下三个条件的内存系统是为coherent
\1. 对于同一地址 X, 若处理器 P 在写后读,并且在 P 的写后没有别的处理器写 X,那么 P 的读总是能返回 P 写入的值。
条件1要求系统提供我们在单处理器中已熟知的程序次序(program order)。
\2. 处理器 P1 完成对 X 的写后,P2 读 X. 如果两者之间相隔时间足够长,并且没有其他处理器写 X, 那么 P2 可以获得 P1 写入的值。
条件2要求写结果最终对别的处理器可见。
\3. 对同一地址的写操作是串行的(serialized), 在所有处理器看来,通过不同处理器对X的写操作都是以相同次序进行的。举个例子,如果值 1 先被写入,值 2 后被写入,那么处理器不能先读到值 2, 然后再读到值 1.
性质3要求系统提供写串行化(write serialization). 若这一性质不被满足,程序错误可能会被引发:考虑 P1 先写 P2 后写的情况,如果存在一些处理器先看到P2的写结果,后看到 P1 的值,那么这个处理器将无限期地保持P1写入的值。
虽然上述性质可以充分保证系统coherence的达成,但它仍然未对写操作何时对读操作可见进行描述:考虑P1先写P2后读的情况,如果写读操作间隔很短,P2可能无法获得P1写入的值。
被引用超过一千多次,同时被[1][3] highly recommend 的[2]作为了解memory consistency model的入门导引,正是定义了写操作的结果何时被读操作获得。
II. Memory consistency model
本质上,内存一致模型限制了**读操作**的返回值。
2.1 Sequential consistency model
2.1.1 什么是sequential consistency
直观上,读操作应该返回“最后”一次写入的值。
1、在单处理器系统中,“最后”由程序次序定义。
2、在多处理器系统中,我们称之为顺序连贯(sequential consistency, SC).
通俗地说,SC要求所有内存操作表现为(appear)逐个执行(任一次的执行结果都像是所有处理器的操作都以某种次序执行),每个处理器中的操作都以其程序指定的次序执行。SC有两点要求:
\1. 在每个处理器内,维护每个处理器的程序次序;
\2. 在所有处理器间,维护单一的表征所有操作的次序。对于写操作W1, W2, 不能出现从处理器 P1 看来,执行次序为 W1->W2; 从处理器 P2 看来,执行次序却为 W2->W1 这种情况。
这使得内存操作需要表现为原子执行(瞬发执行):可以想象系统由单一的全局内存组成,每一时刻,由switch将内存连向任意的处理器,每个处理器按程序顺序发射(issue)内存操作。这样,switch就可以提供全局的内存串行化性质。
考虑下面程序:


图2. SC的两个要求(引自[2] Figure 2. Examples for sequential consistency)
图 2a 阐述了 SC 对程序次序的要求(要求一)。当处理器 P1 想要进入临界区时,
它先将 Flag1 更新为 1, 再去判断 P2 是否尝试进入临界区(Flag2). 若 Flag2 为 0, 表示 P2 未尝试进入临界区,此时 P1 可以安全进入临界区。
1、这个算法假设如果 P1 中读到 Flag2 等于0, 那么P1的写操作(Flag1=1)会在P2 的写操作和读操作之前发生,这可以避免 P2 也进入临界区。SC 通过维护程序次序来保证这一点。
图 2b 阐述了原子性要求。原子性允许我们假设 P1 对 A 的写操作对整个系统(P2, P3) 是同时可见的:
\1. P1 将 A 写成1;
\2. P2 先看到 P1 写 A 后才写 B;
\3. P3 看到 P2 写 B 后才去读 A, P3 此时读出的 A 必须要是 1 (而不会是0)
\4. 因为从 P2 看来操作执行次序为 (A=1)->(B=1), 不允许P3在看到操作 B=1 时,没有看到 A=1.
2.1.2 实现Sequential consistency
为实现SC,要考虑它与常见硬件优化间的冲突。
2.1.2.1 在无缓存的体系结构下实现SC
对于无缓存的体系结构,[2]以三个常见硬件优化为例,讨论了SC与它们间的冲突及解决办法:
1、带有读旁路的写缓冲(Write buffers with read bypassing)
读操作可以不等待写操作,导致后续的读操作越过前面的写操作,违反程序次序
2、重叠写(Overlapping writes)
对于不同地址的多个写操作同时进行,导致后续的写操作越过前面的读操作,违反程序次序
3、非阻塞读(Nonblocking reads)
多个读操作同时进行,导致后续的读操作越过前面的读操作先执行,违反程序次序
为解决上述硬件优化对SC带来的问题,[2]提出了程序次序要求(program order requirement): 按照程序次序,处理器的上一次内存操作需要在下一次内存操作前完成。 ([2]中针对每个冲突提出了特定的解决方法,在此不展开)
2.1.2.2 在有缓存的体系结构下实现SC
2.2 Relaxed consistency model
为获得好的性能,我们可以引入放松内存一致性模型(relaxed memory consistency model**s**),**这些**模型主要通过两种方式优化程序(读写):
-
放松对程序次序的要求:这种放松与此前所述的“在无缓存的体系结构中采用的优化”类似,**仅适用于**对不同地址的操作对(opeartion pairs)间使用。
-
放松对写原子性的要求:一些模型允许读操作在“一个写操作未对所有处理器可见”前返回值。这种放松**仅适用于**基于缓存的体系结构。
我们用A->B表示 A 先于 B 完成,[1] Chapter 5.6 根据放松的操作对次序,给出了多种内存模型:
-
放松 W->R的模型, 称为total store ordering或processor consistency. 这种序列模型仍保持了写(store)操作间的次序;
-
放松 W->W的模型, 称为partial store ordering
-
放松 R->W 和 R->R的模型有很多种:
-
Weak ordering
-
Power PC consistency model
- Release consistency
通过放松这些次序,处理器可能获得显著的性能提升。
[2] 针对这些模型的复杂性(放松不同操作对的优势和复杂性,一个写操作何时才算完成,以及决定处理器何时能看到它自己修改的值等)做了相对详尽的描述,在此不展开。
III. C++11 memory order
[3] Chapter 5.3 Synchronizing operations and enforcing order介绍了下述内存关系与内存次序。
3.1 Synchronized-with 与 happens-before 关系
考虑下述程序:
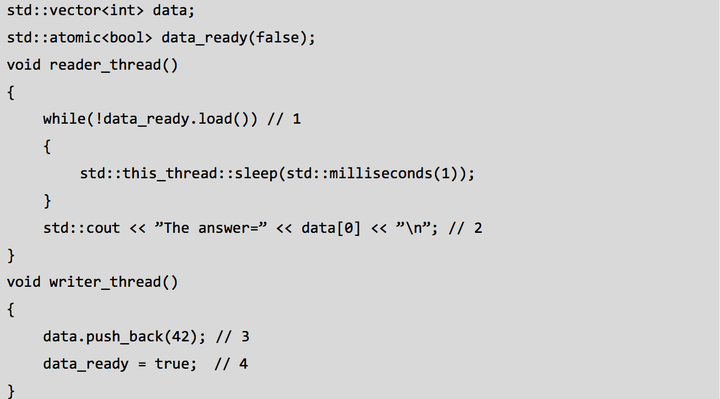
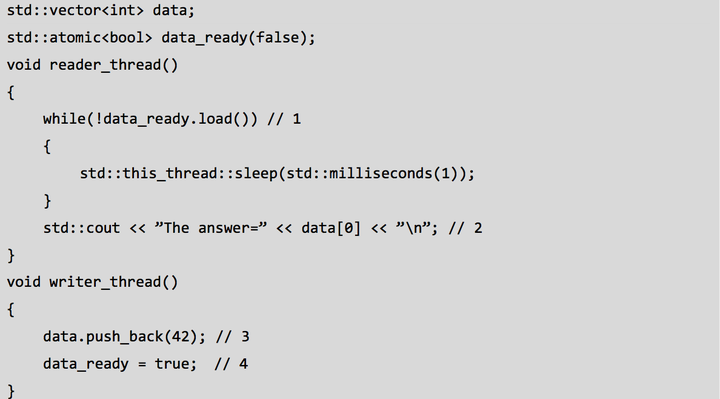
图5 . 通过不同线程读写变量(引自[3] Listing 5.2 Reading and writing variables from different threads)
注意到,非原子性的读(2)和写(3)若在没有强制顺序的情况下访问同一变量,
将导致未定义行为。原子变量 data_ready 通过内存模型关系中的 happens-before 和 synchronized-with, 为它们 供了必要的顺序:
1、 写 data(3)在写 data_ready(4)前发生(happens-before);
2、写 data_ready(4)在读出 data_ready 的值为真(1)前发生(happens-before);
3、data_ready 的值为真(1)在读 data(2)前发生(happens-before).
通过 happens-before 的传递性及引入原子变量,我们保证了读写间的顺序。 默认的原子操作使得写变量在读变量之前发生,然而原子操作也有用其他可选的操作方式,我们在此先介绍 synchronized-with 和 happens-before 关系。
3.1.1 Synchronized-with 关系
该关系 描述的是,对于suitably tagged**(如默认的memory_order_seq_cst)**在变量 x 上的写操作 W(x) synchronized-with 在该变量上的读操作 R(x), 这个读操作欲读取的值是 W(x) 或同一线程随后的在 x 上的写操作 W’, 或任意线程一系列的在 x 上的 read-modify-write 操作(如 fetch_add()或 compare_exchange_weak())而这一系列操作最初读到 x 的值是 W(x) 写入的值。
简单地说,如果线程 A 写了变量 x, 线程 B 读了变量 x, 那么我们就说线程 A, B 间存在 synchronized-with 关系。
3.1.2 Happens-before 关系
Happens-before 指明了哪些指令将看到哪些指令的结果。
对于单线程而言,这很明了:如果一个操作 A 排列在另一个操作 B 之前,那 么这个操作 A happens-before B. 但如果多个操作发生在一条声明中(statement), 那么通常他们是没有 happens-before 关系的,因为他们是未排序的。当然这也有 例外,比如逗号表达式。
对于多线程而言,如果一个线程中的操作 A inter-thread happens-before 另一个线程中的操作 B, 那么 A happens-before B.
Inter-thread happens-before 关系
Inter-thread happens-before 概念相对简单,并依赖于 synchronized-with 关系: 如果一个线程中的操作 A synchronized-with 另一个线程中的操作 B, 那么 A inter-thread happens-before B. Inter-thread happens-before 关系具有传递性。
Inter-thread happens-before 可以与 sequenced-before 关系结合:如果 A sequenced-before B, B inter-thread happens-before C, 那么 A inter-thread happens-before C. 这揭示了如果你在一个线程中对数据进行了一系列操作,那么你只需要一个 synchronized-with 关系,即可使得数据对于另一个执行操作 C 的线程可 见。
3.2 C++11 memory order
C++11 述了 6 种可以应用于原子变量的内存次序:
-
momory_order_relaxed,
-
memory_order_consume,
- memory_order_acquire,
- memory_order_release,
- memory_order_acq_rel,
- memory_order_seq_cst.
虽然共有 6 个选项,但它们表示的是三种内存模型:
-
sequential consistent(memory_order_seq_cst),
-
relaxed(memory_order_seq_cst).
- acquire release(memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel),
这些不同的内存序模型在不同的CPU架构下会有不同的代价。这允许专家通过采用更合理的内存序获得更大的性能 升;同时允许在对性能要求不是那么严格的程序中采用默认的内存序,使得程序更容易理解。
不同的内存序模型与 synchronized-with 关系结合时,将产生不同的结果。
3.2.1 顺序一致次序(sequential consisten ordering)
对应memory_order_seq_cst.
SC作为默认的内存序,是因为它意味着将程序看做是一个简单的序列。如果对于一个原子变量的操作都是顺序一致的,那么多线程程序的行为就像是这些操作都以一种特定顺序被单线程程序执行。
从同步的角度来看,一个顺序一致的 store 操作 synchroniezd-with 一个顺序一致的需要读取相同的变量的 load 操作。除此以外,顺序模型还保证了在 load 之后执行的顺序一致原子操作都得表现得在 store 之后完成。
非顺序一致内存次序(non-sequentially consistency memory ordering)强调对同一事件(代码),不同线程可以以不同顺序去执行,不仅是因为编译器可以进行指令重排,也因为不同的 CPU cache 及内部缓存的状态可以影响这些指令的执行。但所有线程仍需要对某个变量的连续修改达成顺序一致。
3.2.2 松弛次序(relaxed ordering)
对应memory_order_relaxed.
在原子变量上采用 relaxed ordering 的操作不参与 synchronized-with 关系。在同一线程内对同一变量的操作仍保持happens-before关系,但这与别的线程无关。 在 relaxed ordering 中唯一的要求是在同一线程中,对同一原子变量的访问不可以被重排。
没有附加同步的情况下,“对每个变量的修改次序”(我的理解是对每个变量的写串行化)是唯一一件被多个线程共享的事。
3.2.3 获取-释放次序(acquire-release ordering)
对应memory_order_release, memory_order_acquire, memory_order_acq_rel.
Acquire-release 中没有全序关系,但它 供了一些同步方法。在这种序列模 型下,原子 load 操作是 acquire 操作(memory_order_acquire), 原子 store 操作是 release操作(memory_order_release), 原子read_modify_write操作(如fetch_add(), exchange())可以是 acquire, release 或两者皆是(memory_order_acq_rel). 同步是 成对出现的,它出现在一个进行 release 操作和一个进行 acquire 操作的线程间。 一个 release 操作 syncrhonized-with 一个想要读取刚才被写的值的 acquire 操作。
这意味着不同线程仍然看到了不一样的次序,但这次序是被限制过了的。当我们在此再引入 happens-before 关系时,就可以实现更大规模的顺序关系。([3] Listing 5.8, 5.9)
3.2.4 acquire-release间的数据依赖与memory_order_consume
memory_order_consume 是 acquire-release 顺序模型中的一种,但它比较特殊,它为 inter-thread happens-before 引入了数据依赖关系:dependency-ordered-before 和 carries-a-dependency-to.
如同 sequenced-before, carries-a-dependency-to 严格应用于单个进程,建立了 操作间的数据依赖模型:如果操作 A 的结果被操作 B 作为操作数,那么 A carries-a-dependency-to B. 这种关系具有传递性。
dependency-ordered-before 可以应用于线程与线程之间。这种关系通过一个 原子的被标记为 memory_order_consume 的 load 操作引入。这是 memory_order_acquire 内存序的特例:它将同步数据限定为具有直接依赖的数据。 一个被标记为 memory_order_release, memory_order_acq_rel 或 memory_order_seq_cst 的原子 store 操作 A dependency-ordered-before 一个被标记为 memory_order_consume 的欲读取刚被改写的值的原子 load 操作 B. 同时,如果 A dependency-order-before B, 那么 A inter-thread happens-before B.
如果一个 store 操作被标记为 memory_order_release, memory_order_acq_rel 或 memory_order_seq_cst, 一个 load 操作被标记为 memory_order_cunsume, memory_order_acquire 或 memory_order_seq_sct, 一连串 load 中的每个操作,读取的都是之前操作写下的值([3] Listing 5.11 举例说明了这一点),那么这一连串操作将构成 release sequence, 最初的 store 操作 synchronized-with 或 dependency-ordered-before 最后的 load.
不过[3]没有给出任何使用memory_order_consume的代码示例。
参考文献
[3] Williams, Anthony. C++ concurrency in action. Manning; Pearson Education, 2012.