Design and optimize
1、Optimize的目的是提高**并发**,最终目的是提供performance、遵循optimization principle。
2、以Herb Sutter的"Effective concurrency"系列文章为蓝本来进行总结
3、需要基于 hardware CPU 的运行机制来进行优化
案例
jemalloc
NOTE:
1、参见工程
programming-language的library-jemalloc章节NOTE:
1、如何降低lock contention ,这非常重要
2、从下面的描述来看,Larson and Krishnan (1998) 的思想是: "divide to reduce lock granularity",即"They tried pushing locks down in their allocator, so that rather than using a single allocator lock, each free list had its own lock",显然,这降低了lock granularity。
3、jemalloc 借鉴了Larson and Krishnan (1998) 的"multiple arenas"策略,但是"uses a more reliable mechanism than hashing for assignment of threads to arenas",通过后文可知,是"round-robin"
在下面的图中,解释了"hashing of the thread identifiers"的劣势,简单而言: 伪随机过程,并不能够保证均等,因此无法保证load balance(此处使用load balance是不准确的)
One of the main goals for this allocator was to reduce lock contention for multi-threaded applications running on multi-processor systems. Larson and Krishnan (1998) did an excellent job of presenting and testing strategies. They tried pushing locks down in their allocator, so that rather than using a single allocator lock, each free list had its own lock. This helped some, but did not scale adequately, despite minimal lock contention. They attributed this to “cache sloshing” – the quick migration of cached data among processors during the manipulation of allocator data structures. Their solution was to use multiple arenas for allocation, and assign threads to arenas via hashing of the thread identifiers (Figure 2). This works quite well, and has since been used by other implementations (Berger et al., 2000; Bonwick and Adams, 2001). jemalloc uses multiple arenas, but uses a more reliable mechanism than hashing for assignment of threads to arenas.
Multiple processors: Use four times as many arenas as there are processors. By assigning threads to a set of arenas, the probability of a single arena being used concurrently decreases.
NOTE:
1、通过分解来降低锁粒度,减少竞争,提高并发性
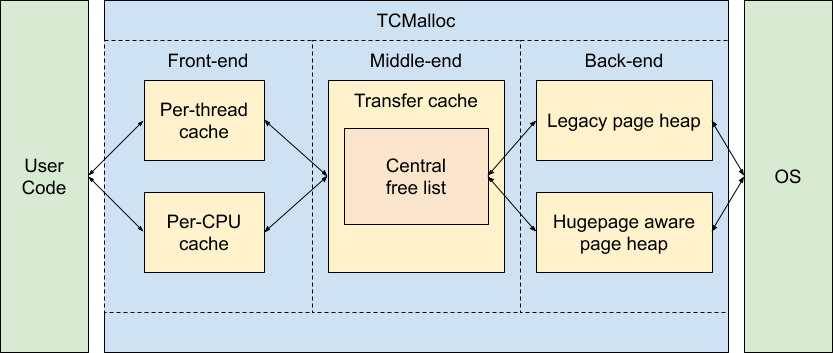
TCMalloc : Thread-Caching Malloc
1、Fast, uncontended allocation and deallocation for most objects. Objects are cached, depending on mode, either per-thread, or per-logical-CPU. Most allocations do not need to take locks, so there is low contention and good scaling for multi-threaded applications.
DB
行级锁、表级锁
Scalable concurrency、 re-enable free lunch、O(n) scalability
Herb Sutter 2005年发表的 The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software 文章,其中总结了CPU的发展方向,对software的影响,programmer要如何做。
在 How-Much-Scalability-Do-You-Have-or-Need 中,提出了如下核心观点:
1、scale well to multiple core CPU
2、能够充分发挥hardware的computation power,理想情况是线性增加: software的处理能力和核数呈线性关系
3、作为software engineer,需要开发出具有scalability的software,这样才能够re-enable the free lunch
查询核数来实现O(n) scalability
为了实现O(n) scalability,可能需要查询核数,下面是一些案例:
1、jemalloc
Pipeline
参见 How-Much-Scalability-Do-You-Have-or-Need 章节。
Read and write tradeoff/根据read and write来选择
在multiple model中,对于shared data的read、write需要进行Concurrency control,在本章总结了多种concurrency control技术,在选择这些技术的时候,非常重要的一点是: read and write tradeoff。
有些技术在read远多于write的时候,是非常有效的。
根据read、write的多少来选择concurrency control technique。
下面是素材:
1、wikipedia Read-copy-update
2、wikipedia Readers–writer lock
3、wikipedia Seqlock
Choose-Concurrency-Friendly-Data-Structures
这是在 12-Choose-Concurrency-Friendly-Data-Structures 中提出的。
Divide shared data to 降低lock的粒度、减少线程竞争
这是提高并发的直接做法。
1、jemalloc
2、DB
行级锁、表级锁
draft: cache locality and scalability and contention
如果多个thread都使用(read、write)同一个lock、variable,则就会出现high contention
如果能够让每个thread使用它自己的local variable,那么就能够增加cache local,减少contention,增加scalability。
Per-thread、avoid shared data消除竞争
1、Spinning-lock-optimization
TAS spin lock中,所有的thread都使用同一个shared data→CLH Lock、MCS Lock,每个thread都有要给自己的node,它们只需要poll自己的node。
2、以redis线程模型为例来进行说明,每个thread一个私有的queue,这样有效地避免竞争。
3、tcmalloc
使用non-blocking、lock-less技术
它们都能够避免进入system call。
Thoughts
为了性能,如果加锁的时间不长,可以使用spinning lock,不使用system lock,这样可以避免系统调用问题。
Parallel divide and conquer
关于此,参见:
1、02-How-Much-Scalability-Do-You-Have-or-Need
2、工程discrete的Divide-and-Conquer章节
Cache optimization
避免cache sloshing-晃动
1、jemalloc 就是一个非常好的案例
2、02-How-Much-Scalability-Do-You-Have-or-Need
3、12-Choose-Concurrency-Friendly-Data-Structures
增加cache performance
1、align-to-cache line-optimization
2、padding-to-cache line-optimization-avoid false sharing