preshing Acquire and Release Semantics
Generally speaking, in lock-free programming, there are two ways in which threads can manipulate shared memory:
1、They can compete with each other for a resource, or
2、they can pass information co-operatively from one thread to another.
Acquire and release semantics are crucial(至关重要的) for the latter: reliable passing of information between threads.
NOTE:
1、上面这段话的意思是: 使用**Acquire and release semantics** 对于实现thread之间pass information co-operatively to access shared memory至关重要,也就是: 我们使用**Acquire and release semantics** 来实现lock free
In fact, I would venture(冒进的) to guess that incorrect or missing acquire and release semantics is the #1 type of lock-free programming error.
In this post, I’ll demonstrate various ways to achieve acquire and release semantics in C++. I’ll touch upon the C++11 atomic library standard in an introductory way, so you don’t already need to know it. And to be clear from the start, the information here pertains(适合、属于) to lock-free programming without sequential consistency. We’re dealing directly with memory ordering in a multicore or multiprocessor environment.
Unfortunately, the terms acquire and release semantics appear to be in even worse shape than the term lock-free, in that the more you scour(搜索) the web, the more seemingly contradictory(矛盾的) definitions you’ll find. Bruce Dawson offers a couple of good definitions (credited to Herb Sutter) about halfway through this white paper. I’d like to offer a couple of definitions of my own, staying close to the principles behind C++11 atomics:
Definition
NOTE: 原文并没有本节的标题。
1、本节描述Acquire semantics、Release semantics的含义
2、Acquire semantics、Release semantics是目标、要求,后面Implementation章节描述如何来实现它们
Acquire semantics
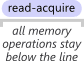
Acquire semantics is a property that can only apply to operations that read from shared memory, whether they are read-modify-write operations or plain loads. The operation is then considered a read-acquire. Acquire semantics prevent memory reordering of the read-acquire with any read or write operation that follows it in program order.
NOTE: 将 Acquire semantics 应用于一个read operation,则就是: read-acquire,**read-acquire**就相当于一条instruction;**read-acquire**对memory reordering有如下要求:
"Acquire semantics prevent memory reordering of the read-acquire with any read or write operation that follows it in program order."
下面的write-release依次类推
Release semantics

Release semantics is a property that can only apply to operations that write to shared memory, whether they are read-modify-write operations or plain stores. The operation is then considered a write-release. Release semantics prevent memory reordering of the write-release with any read or write operation that precedes it in program order.
Implementation
NOTE: 本节描述如何来实现Acquire semantics、Release semantics
Once you digest the above definitions, it’s not hard to see that acquire and release semantics can be achieved using simple combinations of the memory barrier types I described at length in my previous post. The barriers must (somehow) be placed after the read-acquire operation, but before the write-release. [Update: Please note that these barriers are technically more strict than what’s required for acquire and release semantics on a single memory operation, but they do achieve the desired effect.]
NOTE: 下面的"With Explicit Platform-Specific Fence Instructions"章节的例子非常形象地说明了上面这一段的内容;

NOTE: 上面这张图要如何来理解?
acquire semantic: 使用 loadload、loadstore,因为: "Acquire semantics prevent memory reordering of the read-acquire with any read or write operation that follows it in program order."
release semantic: 使用loadstore、storestore,因为: "Release semantics prevent memory reordering of the write-release with any read or write operation that precedes it in program order."
What’s cool is that neither acquire nor release semantics requires the use of a #StoreLoad barrier, which is often a more expensive memory barrier type. For example, on PowerPC, the lwsync (short for “lightweight sync”) instruction acts as all three #LoadLoad, #LoadStore and #StoreStore barriers at the same time, yet is less expensive than the sync instruction, which includes a #StoreLoad barrier.
NOTE: 上面给出的powerpc的实现是非常易懂的,后面就是以它为例
With Explicit Platform-Specific Fence Instructions
One way to obtain the desired memory barriers is by issuing explicit fence instructions. Let’s start with a simple example. Suppose we’re coding for PowerPC, and __lwsync() is a compiler intrinsic(固有的) function that emits the lwsync instruction. Since lwsync provides so many barrier types, we can use it in the following code to establish either acquire or release semantics as needed. In Thread 1, the store to Ready turns into a write-release, and in Thread 2, the load from Ready becomes a read-acquire.

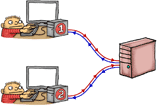
If we let both threads run and find that r1 == 1, that serves as confirmation that the value of A assigned in Thread 1 was passed successfully to Thread 2. As such, we are guaranteed that r2 == 42. In my previous post, I already gave a lengthy analogy for #LoadLoad and #StoreStore to illustrate how this works, so I won’t rehash that explanation here.
synchronized-with
In formal terms, we say that the store to Ready synchronized-with the load. I’ve written a separate post about synchronizes-with here. For now, suffice to say that for this technique to work in general, the acquire and release semantics must apply to the same variable – in this case, Ready – and both the load and store must be atomic operations. Here, Ready is a simple aligned int, so the operations are already atomic on PowerPC.
NOTE: 这段解释非常好,结合前面的内容,我们可以总结实现:
1、the acquire and release semantics must apply to the same variable – flag variable
2、The barriers must (somehow) be placed after the read-acquire operation, but before the write-release.
我们将这种实现方式简记为: write-release-flag-notify-read-acquire-model,显然它能够实现 synchronizes-with ,能够实现: 写成功之后才去读,结合下面的图来理解**写成功之后才去读**: thread1 先write,thread2然后read;
With Fences in Portable C++11
The above example is compiler- and processor-specific. One approach for supporting multiple platforms is to convert the code to C++11. All C++11 identifiers exist in the std namespace, so to keep the following examples brief, let’s assume the statement using namespace std; was placed somewhere earlier in the code.
atomic_thread_fence
C++11’s atomic library standard defines a portable function atomic_thread_fence() that takes a single argument to specify the type of fence. There are several possible values for this argument, but the values we’re most interested in here are memory_order_acquire and memory_order_release. We’ll use this function in place of __lwsync().
There’s one more change to make before this example is complete. On PowerPC, we knew that both operations on Ready were atomic, but we can’t make that assumption about every platform. To ensure atomicity on all platforms, we’ll change the type of Ready from int to atomic<int>. I know, it’s kind of a silly change, considering that aligned loads and stores of int are already atomic on every modern CPU that exists today. I’ll write more about this in the post on synchronizes-with, but for now, let’s do it for the warm fuzzy feeling of 100% correctness in theory. No changes to A are necessary.

The memory_order_relaxed arguments above mean “ensure these operations are atomic, but don’t impose any ordering constraints/memory barriers that aren’t already there.”
Implementation
Once again, both of the above atomic_thread_fence() calls can be (and hopefully are) implemented as lwsync on PowerPC. Similarly, they could both emit a dmb instruction on ARM, which I believe is at least as effective as PowerPC’s lwsync. On x86/64, both atomic_thread_fence() calls can simply be implemented as compiler barriers, since usually, every load on x86/64 already implies acquire semantics and every store implies release semantics. This is why x86/64 is often said to be strongly ordered.
NOTE:这段总结非常好
Without Fences in Portable C++11
In C++11, it’s possible to achieve acquire and release semantics on Ready without issuing explicit fence instructions. You just need to specify memory ordering constraints directly on the operations on Ready:

Think of it as rolling each fence instruction into the operations on Ready themselves. [Update: Please note that this form is not exactly the same as the version using standalone fences; technically, it’s less strict.] The compiler will emit any instructions necessary to obtain the required barrier effects. In particular, on Itanium, each operation can be easily implemented as a single instruction: ld.acq and st.rel. Just as before, r1 == 1 indicates a synchronizes-with relationship, serving as confirmation that r2 == 42.
This is actually the preferred way to express acquire and release semantics in C++11. In fact, the atomic_thread_fence() function used in the previous example was added relatively late in the creation of the standard.
Acquire and Release While Locking
NOTE: 这段总结了:
1、Acquire and Release 命名的来源和 mutex 之间的关联
2、mutex 的 实现
As you can see, none of the examples in this post took advantage of the #LoadStore barriers provided by acquire and release semantics. Really, only the #LoadLoad and #StoreStore parts were necessary. That’s just because in this post, I chose a simple example to let us focus on API and syntax.
One case in which the #LoadStore part becomes essential is when using acquire and release semantics to implement a (mutex) lock. In fact, this is where the names come from: acquiring a lock implies acquire semantics, while releasing a lock implies release semantics! All the memory operations in between are contained inside a nice little barrier sandwich, preventing any undesireable memory reordering across the boundaries.

Here, acquire and release semantics ensure that all modifications made while holding the lock will propagate fully to the next thread that obtains the lock. Every implementation of a lock, even one you roll on your own, should provide these guarantees. Again, it’s all about passing information reliably between threads, especially in a multicore or multiprocessor environment.
In a followup post, I’ll show a working demonstration of C++11 code, running on real hardware, which can be plainly observed to break if acquire and release semantics are not used.