csdn 聊聊高并发(五)理解缓存一致性协议以及对并发编程的影响
NOTE:
1、从hardware的角度分析了影响concurrency的因素,这是非常好的,这是从根本上进行的分析
一个基本的CPU执行计算的过程如下:
-
程序以及数据被加载到主内存
-
指令和数据被加载到CPU的高速缓存
-
CPU执行指令,把结果写到高速缓存
-
高速缓存中的数据写回主内存
NOTE:
1、相当于load and store
这个过程中,我们可以看到有两个问题
1、现代的计算芯片都会集成一个L1高速缓存,我们可以理解为每个芯片都有一个私有的存储空间。那么当CPU的不同计算芯片要访问同一个内存地址时,该内存地址的值会在CPU的不同计算芯片之间有多个拷贝,如何同步这些拷贝?
2、CPU读写是直接和高速缓存打交道,而不是和主内存直接打交道。因为通常一次主存访问在几十到几百个时钟周期,而一次L1高速缓存的读写只需要1-2个时钟周期,而一次L2高速缓存的读写只需要数十个时钟周期。那么CPU写到高速缓存的值何时写回到主内?如果是多个计算芯片在处理同一个内存地址,那么如何处理这个时间差是个问题。
互连结构 和 互连线
互连线
对于第一个问题,不同的硬件结构处理的方式不一样。我们来理解一下**互连线**的概念。
**互连线**是处理器于主存以及处理器与处理器之间进行通信的媒介,有两种基本的互联结构:SMP(symmetric multiprocessing 对称多处理)和NUMA(nonuniform memory access 非一致内存访问)
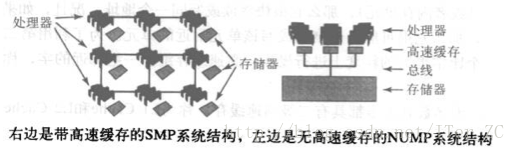
SMP系统结构
SMP系统结构**非常普通,因为它们最容易构建,很多小型服务器采用这种结构。处理器和存储器之间采用**总线**互联,处理器和存储器都有负责发送和监听总线广播的信息的**总线控制单元。但是同一时刻只能有一个处理器(或存储控制器)在总线上广播,所有的处理器都可以监听。
很容易看出,对总线的使用是**SMP结构**的瓶颈。
NOTE:
1、结构决定性质
NUMA
NOTE:
1、没有读懂
NUMP系统结构中,一系列节点通过点对点网络互联,像一个小型互联网,每个节点包含一个或多个处理器和一个本地存储器。一个节点的本地存储对于其他节点是可见的,所有节点的本地存储一起形成了一个可以被所有处理器共享的全局存储器。可以看出,NUMP的本地存储是共享的,而不是私有的,这点和SMP是不同的。NUMP的问题是网络比总线复制,需要更加复杂的协议,处理器访问自己节点的存储器速度快于访问其他节点的存储器。NUMP的扩展性很好,所以目前很多大中型的服务器在采用NUMP结构。
互连线是决定因素
对于上层程序员来说,最需要理解的是互连线是一种重要的资源,使用的好坏会直接影响程序的执行性能。
缓存一致性协议
大概理解了不同的互连结构之后,我们来看看缓存一致性协议。它主要就是处理多个处理器处理同一个主存地址的问题。
缓存一致性流量风暴
NOTE:
1、将此称为CAS-cache coherence flood
2、How-Cache-Coherency-Impacts-Power-Performance
缓存一致性协议存在的一个最大的问题是可能引起缓存一致性流量风暴,之前我们看到总线在同一时刻只能被一个处理器使用,当有大量缓存被修改,或者同一个缓存块一直被修改时,会产生大量的缓存一致性流量,从而占用总线,影响了其他正常的读写请求。
一个最常见的例子就是如果多个线程对同一个变量一直使用CAS操作,那么会有大量修改操作,从而产生大量的缓存一致性流量,因为每一次CAS操作都会发出广播通知其他处理器,从而影响程序的性能。
后面我们会讲如何优化这种使用方式。
对于第二个问题,如何处理修改数据从高速缓存到主内存的时间差,通常使用内存屏障来处理,后面会有专门的主题。
转载请注明来源:http://blog.csdn.net/iter_zc