kegel The C10K problem
[Help save the best Linux news source on the web -- subscribe to Linux Weekly News!]
It's time for web servers to handle ten thousand clients simultaneously, don't you think? After all, the web is a big place now.
And computers are big, too. You can buy a 1000MHz machine with 2 gigabytes of RAM and an 1000Mbit/sec Ethernet card for $1200or so. Let's see - at 20000 clients, that's 50KHz, 100Kbytes, and 50Kbits/sec per client. It shouldn't take any more horsepower(马力) than that to take four kilobytes from the disk and send them to the network once a second for each of twenty thousand clients. (That works out to $0.08 per client, by the way. Those $100/client licensing fees some operating systems charge are starting to look a little heavy!) So hardware is no longer the bottleneck.
NOTE: 电脑也很大。 您可以以1200美元的价格购买带有2 GB RAM和1000Mbit / sec以太网卡的1000MHz机器。 让我们看看 - 在20000个客户端,每个客户端的50KHz,100Kbytes和50Kbits / sec。 它不应该采取任何更多的马力(马力)从盘中取出4千字节并将它们每秒发送到网络一次,每2万个客户端。 (顺便提一下,每个客户的费用为0.08美元。一些操作系统收费的100美元/客户许可费用开始变得有点沉重!)因此硬件不再是瓶颈。
In 1999 one of the busiest ftp sites, cdrom.com, actually handled 10000 clients simultaneously through a Gigabit Ethernet pipe. As of 2001, that same speed is now being offered by several ISPs, who expect it to become increasingly popular with large business customers.
And the thin client model of computing appears to be coming back in style -- this time with the server out on the Internet, serving thousands of clients.
With that in mind, here are a few notes on how to configure operating systems and write code to support thousands of clients. The discussion centers around Unix-like operating systems, as that's my personal area of interest, but Windows is also covered a bit.
Related Sites
See Nick Black's excellent Fast UNIX Servers
In October 2003, Felix von Leitner put together an excellent web page and presentation about network scalability, complete with benchmarks comparing various networking system calls and operating systems. One of his observations is that the 2.6 Linux kernel really does beat the 2.4 kernel, but there are many, many good graphs that will give the OS developers food for thought for some time. (See also the Slashdot comments; it'll be interesting to see whether anyone does followup benchmarks improving on Felix's results.)
NOTE: 2003年10月,Felix von Leitner整理了一个关于网络可扩展性的优秀网页和演示文稿,其中包括比较各种网络系统调用和操作系统的基准测试。 他的一个观察结果是2.6 Linux内核确实击败了2.4内核,但是有很多很好的图表可以让操作系统开发人员在一段时间内深思熟虑。 (另请参阅Slashdot的评论;看看是否有人会根据Felix的结果改进后续基准,这将会很有趣。)
Book to Read First
If you haven't read it already, go out and get a copy of Unix Network Programming : Networking Apis: Sockets and Xti (Volume 1) by the late W. Richard Stevens. It describes many of the I/O strategies and pitfalls related to writing high-performance servers. It even talks about the 'thundering herd' problem. And while you're at it, go read Jeff Darcy's notes on high-performance server design.
(Another book which might be more helpful for those who are using rather than writing a web server is Building Scalable Web Sites by Cal Henderson.)
I/O frameworks
Prepackaged libraries are available that abstract some of the techniques presented below, insulating your code from the operating system and making it more portable.
1、ACE, a heavyweight C++ I/O framework, contains object-oriented implementations of some of these I/O strategies and many other useful things. In particular, his Reactor is an OO way of doing nonblocking I/O, and Proactor is an OO way of doing asynchronous I/O.
2、ASIO is an C++ I/O framework which is becoming part of the Boost library. It's like ACE updated for the STL era.
NOTE: ASIO是asynchronous IO,它所采用的是Proactor模式,参看其文档:Proactor and Boost.Asio
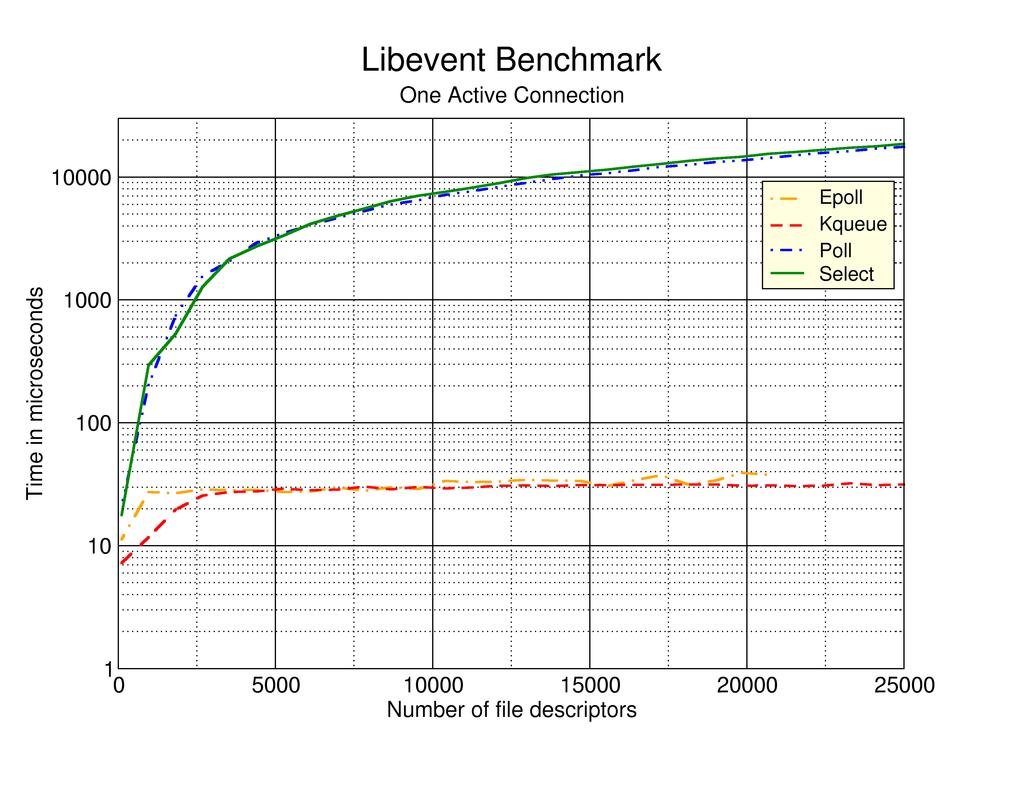
3、libevent is a lightweight C I/O framework by Niels Provos. It supports kqueue and select, and soon will support poll and epoll. It's level-triggered only, I think, which has both good and bad sides. Niels has a nice graph of time to handle one event as a function of the number of connections. It shows kqueue and sys_epoll as clear winners.
{kind=link}
4、My own attempts at lightweight frameworks (sadly, not kept up to date):
- Poller is a lightweight C++ I/O framework that implements a level-triggered readiness API using whatever underlying readiness API you want (
poll,select,/dev/poll,kqueue, orsigio). It's useful for benchmarks that compare the performance of the various APIs. This document links to Poller subclasses below to illustrate how each of the readiness APIs can be used. - rn is a lightweight C I/O framework that was my second try after Poller. It's lgpl (so it's easier to use in commercial apps) and C (so it's easier to use in non-C++ apps). It was used in some commercial products.
6、Matt Welsh wrote a paper in April 2000 about how to balance the use of worker thread and event-driven techniques when building scalable servers. The paper describes part of his Sandstorm I/O framework.
7、Cory Nelson's Scale! library - an async socket, file, and pipe I/O library for Windows
I/O Strategies
Designers of networking software have many options. Here are a few:
1、Whether and how to issue multiple I/O calls from a single thread(单线程中如何issue多个I/O调用)
1.1、Don't; use blocking/synchronous calls throughout, and possibly use multiple threads or processes to achieve concurrency
NOTE : 这句话的意思是不使用single thread,而是使用multiple thread或multiple process来完成concurrency。
1.2、Use nonblocking calls (e.g. write() on a socket set to O_NONBLOCK) to start I/O, and readiness notification (e.g. poll() or /dev/poll) to know when it's OK to start the next I/O on that channel. Generally only usable with network I/O, not disk I/O.
1.3、Use asynchronous calls (e.g. aio_write()) to start I/O, and completion notification (e.g. signals or completion ports) to know when the I/O finishes. Good for both network and disk I/O.
NOTE: 其实上面三段所描述的是三种IO strategy,在APUE的chapter 14 advanced I/O中都有描述;
2、How to control the code servicing each client
2.1、one process for each client (classic Unix approach, used since 1980 or so)
2.2、one OS-level thread handles many clients; each client is controlled by:
- a user-level thread (e.g. GNU state threads, classic Java with green threads)
- a state machine (a bit esoteric, but popular in some circles; my favorite)
- a continuation (a bit esoteric, but popular in some circles)
2.3、one OS-level thread for each client (e.g. classic Java with native threads)
2.4、one OS-level thread for each active client (e.g. Tomcat with apache front end; NT completion ports; thread pools)
2.5、Whether to use standard O/S services, or put some code into the kernel (e.g. in a custom driver, kernel module, or VxD)
The following five combinations seem to be popular:
- Serve many clients with each thread, and use nonblocking I/O and level-triggered readiness notification
- Serve many clients with each thread, and use nonblocking I/O and readiness change notification
- Serve many clients with each server thread, and use asynchronous I/O
- serve one client with each server thread, and use blocking I/O
- Build the server code into the kernel
1. Serve many clients with each thread, and use nonblocking I/O and level-triggered readiness notification
Serve many clients with each thread的意思是:为每个线程提供许多客户端,它实际上所指为一个thread处理多个client;
... set nonblocking mode on all network handles, and use select() or poll() to tell which network handle has data waiting. This is the traditional favorite. With this scheme, the kernel tells you whether a file descriptor is ready, whether or not you've done anything with that file descriptor since the last time the kernel told you about it. (The name 'level triggered' comes from computer hardware design; it's the opposite of 'edge triggered'. Jonathon Lemon introduced the terms in his BSDCON 2000 paper on kqueue().)
NOTE: : 这告诉了我们,
select和poll只能够使用level-triggered readiness notification,而不支持'edge triggered'。
Note: it's particularly important to remember that readiness notification from the kernel is only a hint; the file descriptor might not be ready anymore when you try to read from it. That's why it's important to use nonblocking mode when using readiness notification.
An important bottleneck in this method is that read() or sendfile() from disk blocks if the page is not in core at the moment; setting nonblocking mode on a disk file handle has no effect. Same thing goes for memory-mapped disk files. The first time a server needs disk I/O, its process blocks, all clients must wait, and that raw nonthreaded performance goes to waste.
NOTE: : 当从disk在将文件
read()orsendfile()到core(内存)中时,即使在file handle上设置了**nonblocking mode**,仍然会block;
This is what asynchronous I/O is for, but on systems that lack AIO, worker threads or processes that do the disk I/O can also get around this bottleneck. One approach is to use memory-mapped files, and if mincore() indicates I/O is needed, ask a worker to do the I/O, and continue handling network traffic. Jef Poskanzer mentions that Pai, Druschel, and Zwaenepoel's 1999 Flash web server uses this trick; they gave a talk at Usenix '99 on it. It looks like mincore() is available in BSD-derived Unixes like FreeBSDand Solaris, but is not part of the Single Unix Specification. It's available as part of Linux as of kernel 2.3.51, thanks to Chuck Lever.
NOTE: : This is what asynchronous I/O is for, but on systems that lack
AIO, worker threads or processes that do the disk I/O can also get around this bottleneck.翻译是:这就是异步I / O的用途,但在缺少AIO的系统上,执行磁盘I / O的工作线程或进程也可以解决这个瓶颈问题。它的意思是使用一个thread或者process来执行IO,而不阻塞主线程;
But in November 2003 on the freebsd-hackers list, Vivek Pei et al reported very good results using system-wide profiling of their Flash web server to attack bottlenecks. One bottleneck they found was mincore (guess that wasn't such a good idea after all) Another was the fact that sendfile blocks on disk access; they improved performance by introducing a modified sendfile() that return something like EWOULDBLOCK when the disk page it's fetching is not yet in core. (Not sure how you tell the user the page is now resident... seems to me what's really needed here is aio_sendfile().) The end result of their optimizations is a SpecWeb99 score of about 800 on a 1GHZ/1GB FreeBSD box, which is better than anything on file at spec.org.
2. Serve many clients with each thread, and use nonblocking I/O and readiness change notification
Readiness change notification (or edge-triggered readiness notification) means you give the kernel a file descriptor, and later, when that descriptor transitions from not ready to ready,the kernel notifies you somehow. It then assumes you know the file descriptor is ready, and will not send any more readiness notifications of that type for that file descriptor until you do something that causes the file descriptor to no longer be ready (e.g. until you receive the EWOULDBLOCK error on a send, recv, or accept call, or a send or recv transfers less than the requested number of bytes).
When you use readiness change notification, you must be prepared for spurious events, since one common implementation is to signal readiness whenever any packets are received, regardless of whether the file descriptor was already ready.
This is the opposite of "level-triggered" readiness notification. It's a bit less forgiving of programming mistakes, since if you miss just one event, the connection that event was for gets stuck forever. Nevertheless, I have found that edge-triggered readiness notification made programming nonblocking clients with OpenSSL easier, so it's worth trying.
[Banga, Mogul, Drusha '99] described this kind of scheme in 1999.
3. Serve many clients with each server thread, and use asynchronous I/O
This has not yet become popular in Unix, probably because few operating systems support asynchronous I/O, also possibly because it (like nonblocking I/O) requires rethinking your application. Under standard Unix, asynchronous I/O is provided by the aio_ interface (scroll down from that link to "Asynchronous input and output"), which associates a signal and value with each I/O operation. Signals and their values are queued and delivered efficiently to the user process. This is from the POSIX 1003.1b realtime extensions, and is also in the Single Unix Specification, version 2.
AIO is normally used with edge-triggered completion notification, i.e. a signal is queued when the operation is complete. (It can also be used with level triggered completion notification by calling aio_suspend(), though I suspect few people do this.)
glibc 2.1 and later provide a generic implementation written for standards compliance rather than performance.
Ben LaHaise's implementation for Linux AIO was merged into the main Linux kernel as of 2.5.32. It doesn't use kernel threads, and has a very efficient underlying api, but (as of 2.6.0-test2) doesn't yet support sockets. (There is also an AIO patch for the 2.4 kernels, but the 2.5/2.6 implementation is somewhat different.) More info:
- The page "Kernel Asynchronous I/O (AIO) Support for Linux" which tries to tie together all info about the 2.6 kernel's implementation of AIO (posted 16 Sept 2003)
- Round 3: aio vs /dev/epoll by Benjamin C.R. LaHaise (presented at 2002 OLS)
- Asynchronous I/O Suport in Linux 2.5, by Bhattacharya, Pratt, Pulaverty, and Morgan, IBM; presented at OLS '2003
- Design Notes on Asynchronous I/O (aio) for Linux by Suparna Bhattacharya -- compares Ben's AIO with SGI's KAIO and a few other AIO projects
- Linux AIO home page - Ben's preliminary patches, mailing list, etc.
- linux-aio mailing list archives
- libaio-oracle - library implementing standard Posix AIO on top of libaio. First mentioned by Joel Becker on 18 Apr 2003.
Suparna also suggests having a look at the the DAFS API's approach to AIO
Red Hat AS and Suse SLES both provide a high-performance implementation on the 2.4 kernel; it is related to, but not completely identical to, the 2.6 kernel implementation.
In February 2006, a new attempt is being made to provide network AIO; see the note above about Evgeniy Polyakov's kevent-based AIO.
In 1999, SGI implemented high-speed AIO for Linux. As of version 1.1, it's said to work well with both disk I/O and sockets. It seems to use kernel threads. It is still useful for people who can't wait for Ben's AIO to support sockets.
The O'Reilly book POSIX.4: Programming for the Real World is said to include a good introduction to aio.
A tutorial for the earlier, nonstandard, aio implementation on Solaris is online at Sunsite. It's probably worth a look, but keep in mind you'll need to mentally convert "aioread" to "aio_read", etc.
Note that AIO doesn't provide a way to open files without blocking for disk I/O; if you care about the sleep caused by opening a disk file, Linus suggests you should simply do the open() in a different thread rather than wishing for an aio_open() system call.
Under Windows, asynchronous I/O is associated with the terms "Overlapped I/O" and IOCP or "I/O Completion Port". Microsoft's IOCP combines techniques from the prior art like asynchronous I/O (like aio_write) and queued completion notification (like when using the aio_sigevent field with aio_write) with a new idea of holding back some requests to try to keep the number of running threads associated with a single IOCP constant. For more information, see Inside I/O Completion Ports by Mark Russinovich at sysinternals.com, Jeffrey Richter's book "Programming Server-Side Applications for Microsoft Windows 2000" (Amazon, MSPress), U.S. patent #06223207, or MSDN.
4. Serve one client with each server thread
... and let read() and write() block. Has the disadvantage of using a whole stack frame for each client, which costs memory. Many OS's also have trouble handling more than a few hundred threads. If each thread gets a 2MB stack (not an uncommon default value), you run out of virtual memory at (2^30 / 2^21) = 512 threads on a 32 bit machine with 1GB user-accessible VM (like, say, Linux as normally shipped on x86). You can work around this by giving each thread a smaller stack, but since most thread libraries don't allow growing thread stacks once created, doing this means designing your program to minimize stack use. You can also work around this by moving to a 64 bit processor.
具有为每个客户端使用整个堆栈帧的缺点,这会花费内存。许多操作系统也难以处理超过几百个线程。如果每个线程获得2MB堆栈(不是非常见的默认值),则在32位机器上的(2 ^ 30/2 ^ 21)= 512个线程上耗尽虚拟内存,并且具有1GB用户可访问的VM(例如, Linux通常在x86上发布)。您可以通过为每个线程提供更小的堆栈来解决此问题,但由于大多数线程库在创建后不允许增加线程堆栈,因此这样做意味着设计程序以最大限度地减少堆栈使用。您也可以通过转移到64位处理器来解决这个问题。
The thread support in Linux, FreeBSD, and Solaris is improving, and 64 bit processors are just around the corner even for mainstream users. Perhaps in the not-too-distant future, those who prefer using one thread per client will be able to use that paradigm even for 10000 clients. Nevertheless, at the current time, if you actually want to support that many clients, you're probably better off using some other paradigm.
Linux,FreeBSD和Solaris中的线程支持正在改进,即使对于主流用户,64位处理器也即将到来。也许在不太遥远的未来,那些喜欢每个客户端使用一个线程的人即使对10000个客户端也能够使用这个范例。然而,在目前这个时候,如果你真的想要支持那么多客户,你可能最好还是使用其他一些范例。
For an unabashedly pro-thread viewpoint, see Why Events Are A Bad Idea (for High-concurrency Servers) by von Behren, Condit, and Brewer, UCB, presented at HotOS IX. Anyone from the anti-thread camp care to point out a paper that rebuts this one? :-)
对于一个毫不掩饰的亲线程观点,请参阅HotOS IX上的von Behren,Condit和Brewer,UCB,为什么事件是一个坏主意(对于高并发服务器)。反线营地的任何人都在指出一篇反驳这篇论文的论文吗? :-)
5. Build the server code into the kernel
Novell and Microsoft are both said to have done this at various times, at least one NFS implementation does this, khttpd does this for Linux and static web pages, and "TUX" (Threaded linUX webserver) is a blindingly fast and flexible kernel-space HTTP server by Ingo Molnar for Linux. Ingo's September 1, 2000 announcement says an alpha version of TUX can be downloaded from ftp://ftp.redhat.com/pub/redhat/tux, and explains how to join a mailing list for more info. The linux-kernel list has been discussing the pros and cons of this approach, and the consensus seems to be instead of moving web servers into the kernel, the kernel should have the smallest possible hooks added to improve web server performance. That way, other kinds of servers can benefit. See e.g. Zach Brown's remarks about userland vs. kernel http servers. It appears that the 2.4 linux kernel provides sufficient power to user programs, as the X15 server runs about as fast as Tux, but doesn't use any kernel modifications.
Bring the TCP stack into userspace
See for instance the netmap packet I/O framework, and the Sandstorm proof-of-concept web server based on it.
Measuring Server Performance
Examples
Nginx is a web server that uses whatever high-efficiency network event mechanism is available on the target OS. It's getting popular; there are even about it (and since this page was originally written, many more, including a of that book.)
- thttpd Very simple. Uses a single process. It has good performance, but doesn't scale with the number of CPU's. Can also use kqueue.
- mathopd. Similar to thttpd.
- fhttpd
- boa
- Roxen
- Zeus, a commercial server that tries to be the absolute fastest. See their tuning guide.
- The other non-Java servers listed at http://www.acme.com/software/thttpd/benchmarks.html
- BetaFTPd
- Flash-Lite - web server using IO-Lite.
- Flash: An efficient and portable Web server -- uses select(), mmap(), mincore()
- The Flash web server as of 2003 -- uses select(), modified sendfile(), async open()
- xitami - uses select() to implement its own thread abstraction for portability to systems without threads.
- Medusa - a server-writing toolkit in Python that tries to deliver very high performance.
- userver - a small http server that can use select, poll, epoll, or sigio
Interesting /dev/poll-based servers
- N. Provos, C. Lever, "Scalable Network I/O in Linux," May, 2000. [FREENIX track, Proc. USENIX 2000, San Diego, California (June, 2000).] Describes a version of thttpd modified to support /dev/poll. Performance is compared with phhttpd.
Interesting epoll-based servers
- ribs2
- cmogstored - uses epoll/kqueue for most networking, threads for disk and accept4