ZooKeeper: A Distributed Coordination Service for Distributed Applications
Design Goals
ZooKeeper is simple.
ZooKeeper allows distributed processes to coordinate with each other through a shared hierarchical namespace which is organized similarly to a standard file system.
NOTE: 这是ZooKeeper的simple特性的内涵: 使用容易理解的data model来实现distributed processes的coordination。data model在后面的章节会进行描述。
The reliability aspects keep it from being a single point of failure.
The strict ordering means that sophisticated synchronization primitives can be implemented at the client.
NOTE: 由client来实现synchronization
ZooKeeper is replicated
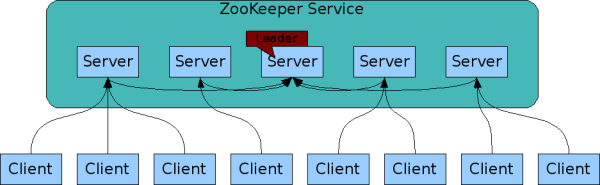
The servers that make up the ZooKeeper service must all know about each other.
NOTE: 从上图可以看出,每个slave server只和leader server进行连接,而slave server之间并没有connection,那这并不是上面这段话中所描述的"know about each other"
ZooKeeper is ordered
ZooKeeper stamps(它的含义非常类似于timestamp) each update with a number that reflects the order of all ZooKeeper transactions. Subsequent operations can use the order to implement higher-level abstractions, such as synchronization primitives.
NOTE:
一、这种技术叫什么名称?非常类似于MVCC;在 ZooKeeper Programmer's Guide 中,对此进行了介绍;
二、上述update具体是指什么?
ZooKeeper is fast
It is especially fast in "read-dominant" workloads.
NOTE: 这让我想到了:
1、RCU
Data model and the hierarchical namespace
ZooKeeper's Hierarchical Namespace
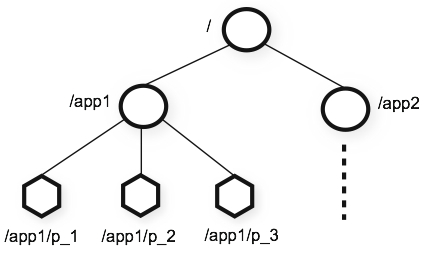
Nodes and ephemeral(短暂的) nodes
(ZooKeeper was designed to store coordination data: status information, configuration, location information, etc., so the data stored at each node is usually small, in the byte to kilobyte range.)
NOTE: 上述**coordination data**,可以是consensus
We use the term znode to make it clear that we are talking about ZooKeeper data nodes.
Znodes maintain a stat structure that includes version numbers for data changes, ACL changes, and timestamps, to allow cache validations and coordinated updates. Each time a znode's data changes, the version number increases. For instance, whenever a client retrieves data it also receives the version of the data.
NOTE: **stat structure**的含义"统计结构"。
The data stored at each znode in a namespace is read and written atomically. Reads get all the data bytes associated with a znode and a write replaces all the data. Each node has an Access Control List (ACL) that restricts who can do what.
ZooKeeper also has the notion of ephemeral nodes. These znodes exists as long as the session that created the znode is active. When the session ends the znode is deleted.
Conditional updates and watches
ZooKeeper supports the concept of watches. Clients can set a watch on a znode.
NOTE: 和redis非常类似
Guarantees
These are:
1、Sequential Consistency - Updates from a client will be applied in the order that they were sent.
NOTE: 关于Sequential Consistency ,参见
Theory\CAP\Consistency章节
2、Atomicity - Updates either succeed or fail. No partial results.
3、Single System Image - A client will see the same view of the service regardless of the server that it connects to. i.e., a client will never see an older view of the system even if the client fails over to a different server with the same session.
4、Reliability - Once an update has been applied, it will persist from that time forward until a client overwrites the update.
NOTE: 一旦应用了更新,它将从那时开始持续存在,直到客户机覆盖该更新
5、Timeliness - The clients view of the system is guaranteed to be up-to-date within a certain time bound.
NOTE: 及时性
Simple API
One of the design goals of ZooKeeper is providing a very simple programming interface. As a result, it supports only these operations:
1、create : creates a node at a location in the tree
2、delete : deletes a node
3、exists : tests if a node exists at a location
4、get data : reads the data from a node
5、set data : writes data to a node
6、get children : retrieves a list of children of a node
7、sync : waits for data to be propagated
NOTE: 就是对tree node的操作,基本上都是"增删改查"
Implementation
ZooKeeper Components shows the high-level components of the ZooKeeper service. With the exception of the request processor, each of the servers that make up the ZooKeeper service replicates its own copy of each of the components.
NOTE:
1、ZooKeeper 使用了自己的consistency protocol: ZAB
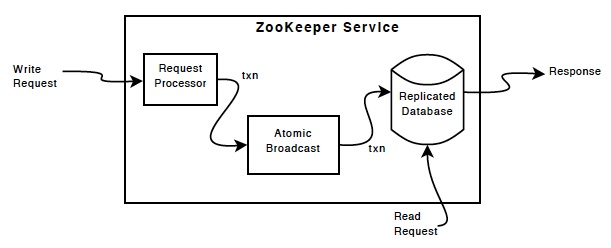
The replicated database is an in-memory database containing the entire data tree. Updates are logged to disk for recoverability, and writes are serialized to disk before they are applied to the in-memory database.
NOTE: 先持久化到文件,然后再更新到memory,这种做法提高了Reliability
Every ZooKeeper server services clients. Clients connect to exactly one server to submit requests. Read requests are serviced from the local replica of each server database. Requests that change the state of the service, write requests, are processed by an agreement protocol.
NOTE: read request能够直接读取local replica,但是write request则需要由agreement protocol来处理,涉及到所有的节点,并且从下面的描述来看,这个过程是比较复杂的:
As part of the agreement protocol all write requests from clients are forwarded to a single server, called the leader. The rest of the ZooKeeper servers, called followers, receive message proposals(建议书) from the leader and agree upon message delivery. The messaging layer takes care of replacing leaders on failures and syncing followers with leaders.
NOTE: 这种协议叫做什么?它是否可靠?
ZooKeeper uses a custom atomic messaging protocol. Since the messaging layer is atomic, ZooKeeper can guarantee that the local replicas never diverge(分离、产生差异). When the leader receives a write request, it calculates what the state of the system is when the write is to be applied and transforms this into a transaction that captures this new state.
NOTE: zookeeper是使用的单个leader,这和redis有什么差异呢?
Performance
ZooKeeper is designed to be highly performance. But is it? The results of the ZooKeeper's development team at Yahoo! Research indicate that it is. (See ZooKeeper Throughput as the Read-Write Ratio Varies.) It is especially high performance in applications where reads outnumber writes, since writes involve synchronizing the state of all servers. (Reads outnumbering writes is typically the case for a coordination service.)